Complete Features
These features were completed when this image was assembled
- Feature complete including (next line)
- OVN-K
Through discussion in this issue, https://issues.redhat.com/browse/OCPBUGS-13966 we have decided port 80 can't be support in conjunction with 433 at this time for the default route ingress.
This needs to be documented for 4.14
As an Openshift admin i want to leverage /dev/fuse in unprivileged containers so that to successfully integrate cloud storage into OpenShift application in a secure, efficient, and scalable manner. This approach simplifies application architecture and allows developers to interact with cloud storage as if it were a local filesystem, all while maintaining strong security practices.
Epic Goal
- Give users the ability to mount /dev/fuse into a pod by default with the `io.kubernetes.cri-o.Devices` annotation
Why is this important?
- It's the first step in a series of steps that allows users to run unprivileged containers within containers
- It also gives access to faster builds within containers
Scenarios
- as a developer on openshift, I would like to run builds within containers in a performant way
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
As a customer, I would like to deploy OpenShift On OpenStack, using the IPI workflow where my control plane would have 3 machines and each machine would have use a root volume (a Cinder volume attached to the Nova server) and also an attached ephemeral disk using local storage, that would only be used by etcd.
As this feature will be TechPreview in 4.15, this will only be implemented as a day 2 operation for now. This might or might not change in the future.
We know that etcd requires storage with strong performance capabilities and currently a root volume backed by Ceph has difficulties to provide these capabilities.
By also attaching local storage to the machine and mounting it for etcd would solve the performance issues that we saw when customers were using Ceph as the backend for the control plane disks.
Gophercloud already accepts to create a server with multiple ephemeral disks:
We need to figure out how we want to address that in CAPO, probably involving a new API; that later would be used in openshift (MAPO, and probably installer).
We'll also have to update the OpenStack Failure Domain in CPMS.
ARO (Azure) has conducted some benckmarks and is now recommending to put etcd on a separated data disk:
https://docs.google.com/document/d/1O_k6_CUyiGAB_30LuJFI6Hl93oEoKQ07q1Y7N2cBJHE/edit
Also interesting thread: https://groups.google.com/u/0/a/redhat.com/g/aos-devel/c/CztJzGWdsSM/m/jsPKZHSRAwAJ
Once we have defined an API for data volumes, we'll need to add support for this new API in MAPO so the user can update their Machines on day 2 to be redeployed with etcd on local disk.
- Day 2 install is documented here (this document was originally created for QE, as a FID).
- We need to document that when using rootVolumes for the Control Plane, etcd should be placed on a local ephemeral disk and we document how.
- We also need to update https://docs.openshift.com/container-platform/4.13/scalability_and_performance/recommended-performance-scale-practices/recommended-etcd-practices.html#move-etcd-different-disk_recommended-etcd-practices with 2 adjustments: the command that is used is mkfs.xfs -f and also we use /dev/vdb.
We only allow usage of controlPlanePort as a TechPreview feature. We should move it to GA.
Open questions:
- does this implies the removal of support for machinesSubnet from the CI jobs and documentation?
Goal
- Goal is to remove Kuryr from the payload and being an SDN option.
Why is this important?
- Kuryr is deprecated, we have a migration path and dropping it means relieving a lot of resources.
Acceptance Criteria
- CI removed in 4.15.
- Images no longer part of the payload.
- Installer not accepting Kuryr as SDN option.
- Docs and release notes updated.
Installer should no longer accept Kuryr as NetworkType. If user choose it, Installer should show clear error about Kuryr no longer being supported.
Since Kuryr removal we don't need to generate the trunks name anymore. They can be removed.
Kuryr is no longer supported in 4.15 and there cannot be a 4.15 cluster with Kuryr, either a new one or upgraded. Therefore we want to remove Kuryr from must-gather.
Epic Goal
- Log linking is a feature implemented where a container can get access to logs of other containers in the pod. To be used in supported configurations, this feature has to be enabled by default in CRI-O
Why is this important?
- Allow this feature for most configurations without a support exception
Scenarios
- as a cluster admin, I would like to easily configure a log forwarder for containers in a pod
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Add it to the OOTB runtime classes to allow access without a custom MC
Feature Overview (aka. Goal Summary)
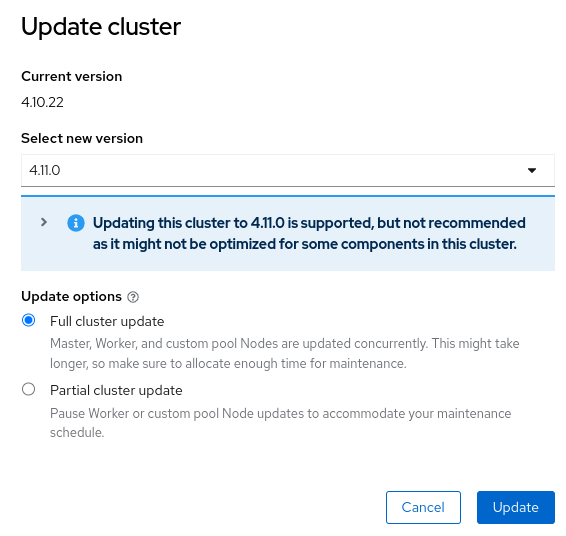
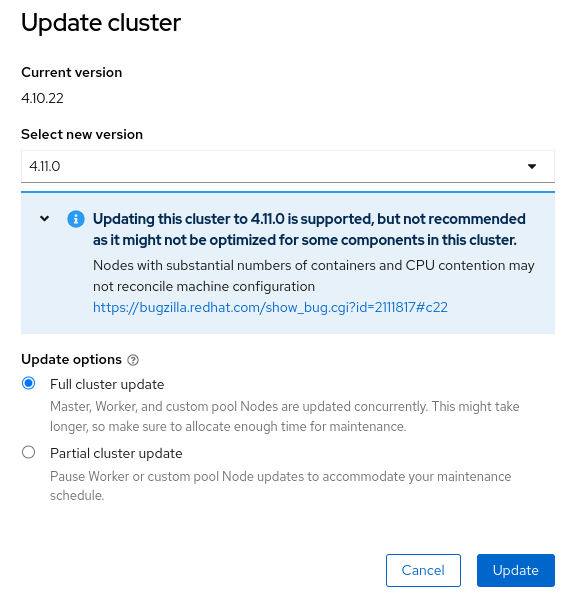
As a cluster-admin I wish to see the status of update and see progress of update on each components.
Background
A common update improvements requested from customer interactions on Update experience is status command
- oc update status ?
From the UI we can see the progress of the update. From oc cli we can see this from "oc get cvo"
But the ask is to show more details in a human-readable format.
Know where the update has stopped. Consider adding at what run level it has stopped.
oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.12.0 True True 16s Working towards 4.12.4: 9 of 829 done (1% complete)
Documentation Considerations
Update docs for UX and CLI changes
Epic Goal*
Add a new command `oc adm upgrade status` command which is backed by an API. Please find the mock output of the command output attached in this card.
Why is this important? (mandatory)
- From the UI we can see the progress of the update. Using OC CLI we can see some of the information using "oc get clusterversion" but the output is not readable and it is a lot of extra information to process.
- Customer as asking us to show more details in a human-readable format as well provide an API which they can use for automation.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Tests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
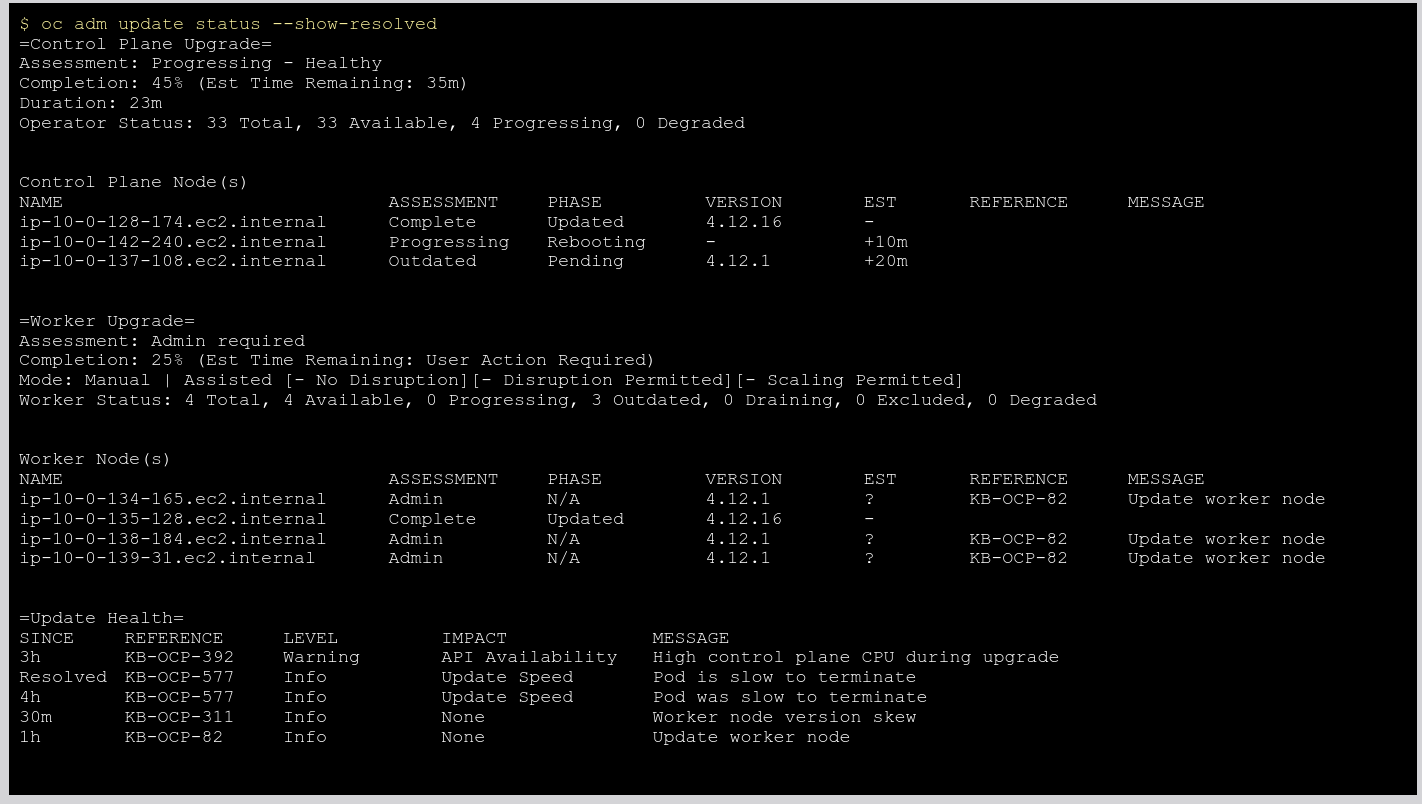
Add control plane update status to "oc adm upgrade status" command output.
Note: In future we want to add "Est Time Remaining: 35m" to this output but need a separate card.
Sample output :
=Control Plane = Assessment: Progressing - Healthy Completion: 45% Duration: 23m Operator Status: 33 Total, 33 Available, 4 Progressing, 0 Degraded
Todo:
- Add code to get similar output
- If this needs a significant code change, please create new Jira cards.
Feature Overview
This feature is about reducing the complexity of the CAPI install system architecture which is needed for using the upstream Cluster API (CAPI) in place of the current implementation of the Machine API for standalone Openshift
prerequisite work Goals
Complete the design of the Cluster API (CAPI) architecture and build the core operator logic needed for Phase-1, incorporating the assets from different repositories to simplify asset management.
Background, and strategic fit
- Initially CAPI did not meet the requirements for cluster/machine management that OCP had the project has moved on, and CAPI is a better fit now and also has better community involvement.
- CAPI has much better community interaction than MAPI.
- Other projects are considering using CAPI and it would be cleaner to have one solution
- Long term it will allow us to add new features more easily in one place vs. doing this in multiple places.
Acceptance Criteria
There must be no negative effect to customers/users of the MAPI, this API must continue to be accessible to them though how it is implemented "under the covers" and if that implementation leverages CAPI is open
Epic Goal
- Rework the current flow for the installation of Cluster API components in OpenShift by addressing some of the criticalities of the current implementation
Why is this important?
- We need to reduce complexity of the CAPI install system architecture
- We need to improve the development, stability and maintainability of Standalone Cluster API on OpenShift
- We need to make Cluster
Acceptance Criteria
- CI - MUST be running successfully with tests automated
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story
As an OpenShift engineer I want the CAPI Providers repositories to use the new generator tool so that they can independently generate CAPI Provider transport ConfigMaps
Background
Once the new CAPI manifests generator tool is ready, we want to make use of that directly from the CAPI Providers repositories so we can avoid storing the generated configuration centrally and independently apply that based on the running platform.
Steps
- Install new CAPI manifest generator as a go `tool` to all the CAPI provider repositories
- Setup a make target under the `/openshift/Makefile` to invoke the generator. Make it output the manifests under `/openshift/manifests`
- Make sure `/openshift/manifests` is mapped to `/manifests` in the openshift/Dockerfile, so that the files are later picked up by CVO
- Make sure the manifest generation works by triggering a manual generation
- Check in the newly generated transport ConfigMap + Credential Requests (to let them be applied by CVO)
Stakeholders
- <Who is interested in this/where did they request this>
Definition of Done
- CAPI manifest generator tool is installed
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
- https://github.com/openshift/cluster-api-provider-aws/pull/471
- https://github.com/openshift/cluster-api/pull/179
- https://github.com/openshift/cluster-api-provider-gcp/pull/209
- https://github.com/openshift/cluster-api-provider-ibmcloud/pull/64
- https://github.com/openshift/cluster-api-provider-vsphere/pull/27
User Story
- As an OpenShift engineer I want to reduce the complexity of the CAPI component installation process so that it is more easily developed and maintainable.
- As an OpenShift engineer I want a way to install CAPI providers depending on the platform the cluster is running on
Background
In order to reduce the complexity in the system we are proposing to get rid of the upstream cluster-api operator (kubernetes-sigs/cluster-api-operator). We plan to replace the responsibility of this component, which at the moment is responsible for reading, fetching and installing the desired providers in cluster, by implementing them directly in the downstream openshift/cluster-capi-operator.
Steps
- Removal of the upstream cluster-api-operator manifest/CRs generation steps from the asset/manifest generator in (https://github.com/openshift/cluster-capi-operator/tree/main/hack/assets), as this component is removed from the system
- Removal of the Cluster Operator controller (which at the moment loads and applies cluster-api-operator CRs)
- Introduction of a new controller within the downstream cluster-capi-operator, called CAPI Installer controller, which is going to be responsible for replacing the duties previously carried out by the Cluster Operator controller + cluster-api-operator, in the following way:
- detection of the current Infrastructure platform the cluster is running on
- loading of the desired CAPI provider manifests at runtime by fetching the relevant transport ConfigMaps (the core and the infrastructure specific one) containing them (there can be multiple CMs per each provider, use label selectors for fetching them, see here).
- extraction of the CAPI provider manifests (CRDs, RBACs, Deployments, Webhooks, Services, ...) from the fetched transport ConfigMaps
- injection of the templated values in such manifests (e.g. ART container images references)
- order aware direct apply of the resulting CAPI providers manifests at runtime (using library-go specific pkgs to apply them where possible)
- continuous tracking of the provider ConfigMaps and reconciliation of the applied CAPI components
- Left to do:
- Rebase changes
- Some boilerplate about creating a new controller
- Apply deployments/daemonsets in a simple way
- Apply correct environment variables to manifests
Stakeholders
- Cluster Infrastructure team
- ShiftStack team
- Hypeshift team
Definition of Done
- Currently CAPI E2E tests should still pass after this refactor
- Improved Docs
- Improved Testing
User Story
As an OpenShift engineer I want to be able to install the new manifest generation tool as a standalone tool in my CAPI Infra Provider repo to generate the CAPI Provider transport ConfigMap(s)
Background
Renaming of the CAPI Asset/Manifest generator from assets (generator) to manifest-gen, as it won't need to generate go embeddable assets anymore, but only manifests that will be referenced and applied by CVO
Steps
- Removal of the `/assets` folder - we are moving away from embedded assets in favour of transport ConfigMaps
- Renaming of the CAPI Asset/Manifest generator from assets (generator) to manifest-gen, as it won't need to generate go embeddable assets anymore, but only manifests that will be referenced and applied by CVO
- Removal of the cluster-api-operator specific code from the assets generator - we are moving away from using the cluster-api-operator
- Remove the assets generator specific references from the Makefiles/hack scripts - they won't be needed anymore as the tool will be referenced only from other repositories
- Adapting the new generator tool to be a standalone go module that can be installed as a tool in other repositories to generate manifests
- Make sure to add CRDs and Conversion,Validation (also Mutation?) Webhooks to the generated transport ConfigMaps
Stakeholders
- Cluster Infrastructure Team
- ShiftStack Team (CAPO)
Definition of Done
- Working and standalone installable generation tool
- https://github.com/openshift/cluster-api-provider-aws/pull/486
- https://github.com/openshift/cluster-api/pull/189
- https://github.com/openshift/cluster-capi-operator/pull/121
- https://github.com/openshift/cluster-api-provider-gcp/pull/214
- https://github.com/openshift/cluster-api-provider-ibmcloud/pull/68
Feature Overview (aka. Goal Summary)
Add support for Johannesburg, South Africa (africa-south1) in GCP
Goals (aka. expected user outcomes)
As a user I'm able to deploy OpenShift in Johannesburg, South Africa (africa-south1) in GCP and this region is fully supported
Requirements (aka. Acceptance Criteria):
A user can deploy OpenShift in GCP Johannesburg, South Africa (africa-south1) using all the supported installation tools for self-managed customers.
The support of this region is backported to the previuos OpenShift EUS release.
Background
Google Cloud has added support for a new region in their public cloud offering and this region needs to be supported for OpenShift deployments as other regions.
Documentation Considerations
The information of the new region needs to be added to the documentation so this is supported.
Epic Goal*
Provide a long term solution to SELinux context labeling in OCP.
Why is this important? (mandatory)
As of today when selinux is enabled, the PV's files are relabeled when attaching the PV to the pod, this can cause timeout when the PVs contains lot of files as well as overloading the storage backend.
https://access.redhat.com/solutions/6221251 provides few workarounds until the proper fix is implemented. Unfortunately these workaround are not perfect and we need a long term seamless optimised solution.
This feature tracks the long term solution where the PV FS will be mounted with the right selinux context thus avoiding to relabel every file.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
- Apply new context when there is none
- Change context of all files/folders when changing context
- RWO & RWX PVs
- ReadWriteOncePod PVs first
- RWX PV in a second phase
As we are relying on mount context there should not be any relabeling (chcon) because all files / folders will inherit the context from the mount context
More on design & scenarios in the KEP and related epic STOR-1173
Dependencies (internal and external) (mandatory)
None for the core feature
However the driver will have to set SELinuxMountSupported to true in the CSIDriverSpec to enable this feature.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development - STOR
- Documentation - STOR
- QE - STOR
- PX -
- Others -
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Epic Goal
Support upstream feature "SELinux relabeling using mount options (CSIDriver API change)"" in OCP as Beta, i.e. test it and have docs for it (unless it's Alpha upstream).
Summary: If Pod has defined SELinux context (e.g. it uses "resticted" SCC) and it uses ReadWriteOncePod PVC and CSI driver responsible for the volume supports this feature, kubelet + the CSI driver will mount the volume directly with the correct SELinux labels. Therefore CRI-O does not need to recursive relabel the volume and pod startup can be significantly faster. We will need a thorough documentation for this.
This upstream epic actually will be implemented by us!
Why is this important?
- We get this upstream feature through Kubernetes rebase. We should ensure it works well in OCP and we have docs for it.
Upstream links
- Enhancement issue: [1710]
- KEP: https://github.com/kubernetes/enhancements/pull/3172
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- External: the feature is currently scheduled for Beta in Kubernetes 1.27, i.e. OCP 4.14, but it may change before Kubernetes 1.27 GA.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Test that the metrics described in the KEP provide useful data. I.e. check that volume_manager_selinux_volume_context_mismatch_warnings_total increases when there are two Pods that have two different SELinux contexts and use the same volume and different subpath of it.
Add metrics described in the upstream KEP to telemetry, so we know how many clusters / Pod would be affected when we expose SELinux mount to all volume types.
We want:
- volume_manager_selinux_container_errors_total + volume_manager_selinux_container_warnings_total + volume_manager_selinux_pod_context_mismatch_errors_total + volume_manager_selinux_pod_context_mismatch_warnings_total - these show user configuration error.
- volume_manager_selinux_volume_context_mismatch_errors_total + volume_manager_selinux_volume_context_mismatch_warnings_total - these show Pods that use the same volume with different SELinux context. This will not be supported when we extend mounting with SELinux to all volume types.
As a cluster user, I want to use mounting with SELinux context without any configuration.
This means OCP ships CSIDriver objects with "SELinuxMount: true" for CSI drivers that support mounting with "-o context". I.e. all CSI drivers that are based on block volumes and use ext4/xfs should have this enabled.
- https://github.com/openshift/alibaba-disk-csi-driver-operator/pull/57
- https://github.com/openshift/azure-disk-csi-driver-operator/pull/93
- https://github.com/openshift/gcp-pd-csi-driver-operator/pull/81
- https://github.com/openshift/ibm-vpc-block-csi-driver-operator/pull/77
- https://github.com/openshift/openstack-cinder-csi-driver-operator/pull/129
- https://github.com/openshift/vmware-vsphere-csi-driver-operator/pull/165
Feature Overview (aka. Goal Summary)
Add support for Dammam, Saudi Arabia, Middle East (me-central2) region in GCP
Goals (aka. expected user outcomes)
As a user I'm able to deploy OpenShift in Dammam, Saudi Arabia, Middle East (me-central2) region in GCP and this region is fully supported
Requirements (aka. Acceptance Criteria):
A user can deploy OpenShift in GCP Dammam, Saudi Arabia, Middle East (me-central2) region using all the supported installation tools for self-managed customers.
The support of this region is backported to the previuos OpenShift EUS release.
Background
Google Cloud has added support for a new region in their public cloud offering and this region needs to be supported for OpenShift deployments as other regions.
Documentation Considerations
The information of the new region needs to be added to the documentation so this is supported.
Elaborate more dashboards (monitoring dashboards, accessible from menu Observe > Dashboards ; admin perspective) related to networking.
Start with just a couple of areas:
- Host network dashboard (using node-exporter network / netstat metrics - related to CMO)
- OVN/OVS health dashboard (using ovn/ovs metrics)
- Ingress dashboard (routes, shards stats) related to Ingress operator / netedge team
(- DNS dashboard, if time)
More info/discussion in this work doc: https://docs.google.com/document/d/1ByNIJiOzd6w5csFYpC27NdOydnBg8Tx45uL4-7v-aCM/edit
Elaborate more dashboards (monitoring dashboards, accessible from menu Observe > Dashboards ; admin perspective) related to networking.
Start with just a couple of areas:
- Host network dashboard (using node-exporter network / netstat metrics - related to CMO)
- OVN/OVS health dashboard (using ovn/ovs metrics)
More info/discussion in this work doc: https://docs.google.com/document/d/1ByNIJiOzd6w5csFYpC27NdOydnBg8Tx45uL4-7v-aCM/edit
Martin Kennelly is our contact point from the SDN team
Create a dashboard from the CNO
Current metrics documentation:
- https://docs.google.com/document/d/1lItYV0tTt5-ivX77izb1KuzN9S8-7YgO9ndlhATaVUg/edit
- https://github.com/ovn-org/ovn-kubernetes/blob/master/docs/metrics.md
Include metrics for:
- pod/svc/netpol setup latency
- ovs/ovn CPU and memory
- network stats: rx/tx bytes, drops, errs per interface (not all interfaces are monitored by default, but they're going to be more configurable via another task:
NETOBSERV-1021)
Feature Overview (aka. Goal Summary)
The OpenShift Assisted Installer is a user-friendly OpenShift installation solution for the various platforms, but focused on bare metal. This very useful functionality should be made available for the IBM zSystem platform.
Goals (aka. expected user outcomes)
Use of the OpenShift Assisted Installer to install OpenShift on an IBM zSystem
Requirements (aka. Acceptance Criteria):
Using the OpenShift Assisted Installer to install OpenShift on an IBM zSystem
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
As a multi-arch development engineer, I would like to ensure that the Assisted Installer workflow is fully functional and supported for z/VM deployments.
Acceptance Criteria
- Feature is implemented, tested, QE, documented, and technically enabled.
- Stories closed.
Description of the problem:
Beside the API there is no possibility to provide the additional kernel arguments to the coreos installer.
In case of zVM installation there are additional kernel arguments required to enable network or storage devices correctly. If not provided the node end up in a emergency shell if node is being rebooted after coreos installation.
This is an example of an API call to install a zVM node. This call need to be executed node specific and after discovery of a node:
curl https://api.openshift.com/api/assisted-install/v2/infra-envs/$
{INFRA_ENV_ID}/hosts/$1/installer-args \
-X PATCH \
-H "Authorization: Bearer ${API_TOKEN}" \
-H "Content-Type: application/json" \
-d '{{ {
"args": [
"--append-karg", "rd.neednet=1",
"--append-karg", "ip=10.14.6.4::10.14.6.1:255.255.255.0:master-1.boea3e06.lnxero1.boe:encbdd0:none",
"--append-karg", "nameserver=10.14.6.1",
"--append-karg", "ip=[fd00::4]::[fd00::1]:64::encbdd0:none",
"--append-karg", "nameserver=[fd00::1]",
"--append-karg", "zfcp.allow_lun_scan=0",
"--append-karg", "rd.znet=qeth,0.0.bdd0,0.0.bdd1,0.0.bdd2,layer2=1",
"--append-karg", "rd.zfcp=0.0.8003,0x500507630400d1e3,0x4000404700000000",{{
"--append-karg", "rd.zfcp=0.0.8103,0x500507630400d1e3,0x4000404700000000"}} ] }{}' | jq
The kernel arguments might differ between discovered nodes.
This applies to zVM only. On KVM (s390x) these additional kernel arguments are not needed.
How reproducible:
Configure a zVM node (in case of SNO) or at least 3 zVM nodes, create a new cluster by choosing a cluster option (SNO or failover) and discover the nodes.
On the UI there is no option to enter the required kernel arguments for the coreos installer.
After verification start installation. Installation failed because nodes could not be rebooted.
Steps to reproduce:
1. Configure at least one zVM node (for SNO) or three for failover accordingly.
2. Discover these nodes
3. Start installation after all validation steps are passed.
Actual results:
Installation failed because cmdline does not contain necessary kernel arguments and the first reboot is failing (nodes are booting into emergency shell).
No option to enter additional kernel arguments on UI.
Expected results:
In case of zVM and Assisted-Installer UI, the user is able to specify the necessary kernel arguments for each discovered zVM nodes. These kernel arguments are passed to the coreos installer and the Installation is successful.
Feature Overview (aka. Goal Summary)
The storage operators need to be automatically restarted after the certificates are renewed.
From OCP doc "The service CA certificate, which issues the service certificates, is valid for 26 months and is automatically rotated when there is less than 13 months validity left."
Since OCP is now offering an 18 months lifecycle per release, the storage operator pods need to be automatically restarted after the certificates are renewed.
Goals (aka. expected user outcomes)
The storage operators will be transparently restarted. The customer benefit should be transparent, it avoids manually restart of the storage operators.
Requirements (aka. Acceptance Criteria):
The administrator should not need to restart the storage operator when certificates are renew.
This should apply to all relevant operators with a consistent experience.
Use Cases (Optional):
As an administrator I want the storage operators to be automatically restarted when certificates are renewed.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
This feature request is triggered by the new extended OCP lifecycle. We are moving from 12 to 18 months support per release.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
No doc is required
Interoperability Considerations
This feature only cover storage but the same behavior should be applied to every relevant components.
The pod `vsphere-problem-detector-operator` mounts the secret:
$ cat assets/vsphere_problem_detector/07_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vsphere-problem-detector-operator
spec:
containers:
volumeMounts:
- mountPath: /var/run/secrets/serving-cert
name: vsphere-problem-detector-serving-cert
volumes:
- name: vsphere-problem-detector-serving-cert
secret:
secretName: vsphere-problem-detector-serving-cert
Hence, if the secret is updated (e.g. as a result of CA cert update), the Pod must be restarted
The pod `csi-snapshot-webhook` mounts the secret:
```
$ cat assets/webhook/deployment.yaml
kind: Deployment
metadata:
name: csi-snapshot-webhook
...
spec:
template:
spec:
containers:
volumeMounts:
- name: certs
mountPath: /etc/snapshot-validation-webhook/certs
volumes:
- name: certs
secret:
secretName: csi-snapshot-webhook-secret
```
Hence, if the secret is updated (e.g. as a result of CA cert update), the Pod must be restarted.
Feature Overview (aka. Goal Summary)
Description of problem:
Even though in 4.11 we introduced LegacyServiceAccountTokenNoAutoGeneration to be compatible with upstream K8s to not generate secrets with tokens when service accounts are created, today OpenShift still creates secrets and tokens that are used for legacy usage of openshift-controller as well as the image-pull secrets.
Customer issues:
Customers see auto-generated secrets for service accounts which is flagged as a security risk.
This Feature is to track the implementation for removing legacy usage and image-pull secret generation as well so that NO secrets are auto-generated when a Service Account is created on OpenShift cluster.
Goals (aka. expected user outcomes)
NO Secrets to be auto-generated when creating service accounts
Requirements (aka. Acceptance Criteria):
Following *secrets need to NOT be generated automatically with every Serivce account creation:*
- ImagePullSecrets : This is needed for Kubelet to fetch registry credentials directly. Implementation needed for the following upstream feature.
https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/2133-kubelet-credential-providers/README.md - Dockerconfig secrets: The openshift-controller-manager relies on the old token secrets and it creates them so that it's able to generate registry credentials for the SAs. There is a PR that was created to remove this https://github.com/openshift/openshift-controller-manager/pull/223.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Concerns/Risks: Replacing functionality of one of the openshift-controller used for controllers that's been in the code for a long time may impact behaviors that w
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Existing documentation needs to be clear on where we are today and why we are providing the above 2 credentials. Related Tracker: https://issues.redhat.com/browse/OCPBUGS-13226
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Openshift-controller-manager has a controller that automatically creates "managed" service accounts that support OpenShift features in every namespace. In OCP 4, this was effectively hard-coded to create the "builder" and "deployer" service accounts.
This controller should be refactored so we have separate instances for the builder and deployer service account, respectively. This will let us disable said controllers via the Capabilities API and ocm-o.
BU Priority Overview
Create custom roles for GCP with minimal set of required permissions.
Goals
Enable customers to better scope credential permissions and create custom roles on GCP that only include the minimum subset of what is needed for OpenShift.
State of the Business
Some of the service accounts that CCO creates, e.g. service account with role roles/iam.serviceAccountUser provides elevated permissions that are not required/used by the requesting OpenShift components. This is because we use predefined roles for GCP that come with bunch of additional permissions. The goal is to create custom roles with only the required permissions.
Execution Plans
TBD
Evaluate if any of the GCP predefined roles in the credentials request manifests of OpenShift cluster operators give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cloud Controller Manager Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of machine api operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster CAPI Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Epic Goal
- ...
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Image Registry Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
Description of problem:
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1.
2.
3.
Actual results:
Expected results:
Additional info:
These are phase 2 items from CCO-188
Moving items from other teams that need to be committed to for 4.13 this work to complete
Epic Goal
- Request to build list of specific permissions to run openshift on GCP - Components grant roles, but we need more granularity - Custom roles now allow ability to do this compared to when permissions capabilities were originally written for GCP
Why is this important?
- Some of the service accounts that CCO creates, e.g. service account with role roles/iam.serviceAccountUser provides elevated permissions that are not required/used by the requesting OpenShift components. This is because we use predefined roles for GCP that come with bunch of additional permissions. The goal is to create custom roles with only the required permissions.
Evaluate if any of the GCP predefined roles in the credentials request manifest of Cluster Storage Operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Evaluate if any of the GCP predefined roles in the credentials request manifest of cloud credentials operator give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
The new GCP provider spec for credentials request CR is as follows:
type GCPProviderSpec struct {
metav1.TypeMeta `json:",inline"`
// PredefinedRoles is the list of GCP pre-defined roles
// that the CredentialsRequest requires.
PredefinedRoles []string `json:"predefinedRoles"`
// Permissions is the list of GCP permissions required to
// create a more fine-grained custom role to satisfy the
// CredentialsRequest.
// When both Permissions and PredefinedRoles are specified
// service account will have union of permissions from
// both the fields
Permissions []string `json:"permissions"`
// SkipServiceCheck can be set to true to skip the check whether the requested roles or permissions
// have the necessary services enabled
// +optional
SkipServiceCheck bool `json:"skipServiceCheck,omitempty"`
}
we can use the following command to check permissions associated with a GCP predefined role
gcloud iam roles describe <role_name>
The sample output for role roleViewer is as follows. The permission are listed in "includedPermissions" field.
[akhilrane@localhost cloud-credential-operator]$ gcloud iam roles describe roles/iam.roleViewer
description: Read access to all custom roles in the project.
etag: AA==
includedPermissions:
- iam.roles.get
- iam.roles.list
- resourcemanager.projects.get
- resourcemanager.projects.getIamPolicy
name: roles/iam.roleViewer
stage: GA
title: Role Viewer
Rather than create custom roles per-cluster, as is currently implemented for GCP, ccoctl should create custom roles per-project due to custom role deletion policies. When a custom role is deleted in GCP it continues to exist and contributes to quota for 7 days. Custom roles are not permanently deleted for up to 14 days after deletion ref: https://cloud.google.com/iam/docs/creating-custom-roles#deleting-custom-role.
Deletion should ignore these per-project custom roles by default and provide an optional flag to delete them.
Since the custom roles must be created per-project, deltas in permissions must be additive. We can't remove permissions with these restrictions since previous versions may rely on those custom role permissions.
Post a warning/info message regarding the permission delta so that users are aware that there are extra permissions and they can clean them up possibly if they're sure they aren't being utilized.
Feature Overview (aka. Goal Summary)
Support Serving OpenShift release signatures via Cincinnati. This can serve mostly disconnected use case.
Currently for disconnected OCP image mirroring we need to create and configure a configmap as mentioned here
Goals (aka. expected user outcomes)
- Remove the need of creating configmap by mirroring signatures from their upstream locations.
- Restricted-network/disconnected Cincinnati can construct the graph-data tarball via a request to Cincinnati instance that already has signature access (e.g. because it's a connected Cincinnati).
Use Cases (Optional):
Connected/disconnected Cincinnati can mirror signatures from their upstream locations without creating configmap using oc-mirror command.
Also, load signatures from a graph-data container image, for the restricted/disconnected-network case.
Background
In the process of mirroring images for a disconnected installation using the "oc-mirror" command, currently signature files located in the release-signatures folder are missing. Currently the files are manually applied to the "openshift-config-managed" namespace. Without this manual step any cluster trying to upgrade fails due to the error the versions are not signed/verified.
Serving OpenShift release signatures via Cincinnati would allow us to have a single service for update related metadata, namely a Cincinnati deployment on the local network, which the CVO will be configured to poll. This would make restricted/disconnected-network updates easier, by reducing the amount of pre-update cluster adjustments (no more need to create signature ConfigMaps in each cluster being updated).
Connected Cincinnati can mirror signatures from their upstream locations.
Cincinnati can also be taught to load signatures from a graph-data container image, for the restricted/disconnected-network case.
Documentation Considerations
Update documentation to remove the need for configmaps
Interoperability Considerations
This impacts oc mirror . There are 2 ways to mirror images as mentioned here .
Epic Goal*
Serving OpenShift release signatures via Cincinnati. This is followup to the OTA-908 epic. In OTA-908 we are focused with respect to the disconnected use case and this epic focuses on getting the same feature working in the hosted OSUS.
Why is this important? (mandatory)
Serving OpenShift release signatures via Cincinnati would allow us to have a single service for update related metadata, namely a Cincinnati deployment on the local network, which the CVO will be configured to poll. This would make restricted/disconnected-network updates easier, by reducing the amount of pre-update cluster adjustments (no more need to create signature ConfigMaps in each cluster being updated).
Scenarios (mandatory)
Current customer workflows like signature ConfigMap creation and ConfigMap application would no longer be required. Instead, cluster-version operators in restricted/disconnected-networks could fetch the signature data from the local OpenShift Update Service (Cincinnati).
Dependencies (internal and external) (mandatory)
The oc-mirror team will need to review/approve oc-mirror changes to take advantage of the new functionality for customers using {{oc-mirror} workflows.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Tests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
Bringing in and implementing the new spec property from OTA-916 (or, if OTA-916 ends up settling on "magically construct a signature store from upstream, implementing that).
This might be helpful context for constructing composite signature stores. Existing CVO-side integration is here, and that would get a bit more complicated with the need to dynamically manage spec-configured signature stores.
Feature Overview
As an Infrastructure Administrator, I want to deploy OpenShift on Nutanix distributing the control plane and compute nodes across multiple regions and zones, forming different failure domains.
As an Infrastructure Administrator, I want to configure an existing OpenShift cluster to distribute the nodes across regions and zones, forming different failure domains.
Goals
Install OpenShift on Nutanix using IPI / UPI in multiple regions and zones.
Requirements (aka. Acceptance Criteria):
- Ensure Nutanix IPI can successfully be deployed with ODF across multiple zones (like we do with vSphere, AWS, GCP & Azure)
- Ensure zonal configuration in Nutanix using UPI is documented and tested
vSphere Implementation
This implementation would follow the same idea that has been done for vSphere. The following are the main PRs for vSphere:
https://github.com/openshift/enhancements/blob/master/enhancements/installer/vsphere-ipi-zonal.md
Existing vSphere documentation
Epic Goal
Nutanix Zonal: Multiple regions and zones support for Nutanix IPI and Assisted Installer
Note
- Nutanix Engineering team is driving this implementation based on the vSphere zonal implementation, led by Yanhua Li .
- The Installer team is expected to just review PRs.
- PRs are expected in these repos:
- https://github.com/openshift/api
- https://github.com/openshift/installer
- https://github.com/openshift/client-go
- https://github.com/openshift/cluster-control-plane-machine-set-operator
- https://github.com/openshift/machine-api-operator
- https://github.com/openshift/machine-api-provider-nutanix
- First PR https://github.com/openshift/api/pull/1578
As a user, I want to be able to spread control plane nodes for an OCP clusters across Prism Elements (zones).
- https://github.com/openshift/installer/pull/7806
- https://github.com/openshift/installer/pull/7730
- https://github.com/openshift/cluster-config-operator/pull/378
- https://github.com/openshift/cluster-control-plane-machine-set-operator/pull/258
- https://github.com/openshift/machine-api-operator/pull/1171
- https://github.com/openshift/machine-api-provider-nutanix/pull/56
This is a followup to https://issues.redhat.com/browse/OPNET-13. In that epic we implemented limited support for dual stack on VSphere, but due to limitations in upstream Kubernetes we were not able to support all of the use cases we do on baremetal. This epic is to track our work up and downstream to finish the dual stack implementation.
This is a followup to https://issues.redhat.com/browse/OPNET-13. In that epic we implemented limited support for dual stack on VSphere, but due to limitations in upstream Kubernetes we were not able to support all of the use cases we do on baremetal. This epic is to track our work up and downstream to finish the dual stack implementation.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Feature Goal
- Enable platform=external to support onboarding new partners, e.g. Oracle Cloud Infrastructure and VCSP partners.
- Create a new platform type, working name "External", that will signify when a cluster is deployed on a partner infrastructure where core cluster components have been replaced by the partner. “External” is different from our current platform types in that it will signal that the infrastructure is specifically not “None” or any of the known providers (eg AWS, GCP, etc). This will allow infrastructure partners to clearly designate when their OpenShift deployments contain components that replace the core Red Hat components.
This work will require updates to the core OpenShift API repository to add the new platform type, and then a distribution of this change to all components that use the platform type information. For components that partners might replace, per-component action will need to be taken, with the project team's guidance, to ensure that the component properly handles the "External" platform. These changes will look slightly different for each component.
To integrate these changes more easily into OpenShift, it is possible to take a multi-phase approach which could be spread over a release boundary (eg phase 1 is done in 4.X, phase 2 is done in 4.X+1).
OCPBU-5: Phase 1
- Write platform “External” enhancement.
- Evaluate changes to cluster capability annotations to ensure coverage for all replaceable components.
- Meet with component teams to plan specific changes that will allow for supplement or replacement under platform "External".
- Start implementing changes towards Phase 2.
OCPBU-510: Phase 2
- Update OpenShift API with new platform and ensure all components have updated dependencies.
- Update capabilities API to include coverage for all replaceable components.
- Ensure all Red Hat operators tolerate the "External" platform and treat it the same as "None" platform.
OCPBU-329: Phase.Next
- TBD
Why is this important?
- As partners begin to supplement OpenShift's core functionality with their own platform specific components, having a way to recognize clusters that are in this state helps Red Hat created components to know when they should expect their functionality to be replaced or supplemented. Adding a new platform type is a significant data point that will allow Red Hat components to understand the cluster configuration and make any specific adjustments to their operation while a partner's component may be performing a similar duty.
- The new platform type also helps with support to give a clear signal that a cluster has modifications to its core components that might require additional interaction with the partner instead of Red Hat. When combined with the cluster capabilities configuration, the platform "External" can be used to positively identify when a cluster is being supplemented by a partner, and which components are being supplemented or replaced.
Scenarios
- A partner wishes to replace the Machine controller with a custom version that they have written for their infrastructure. Setting the platform to "External" and advertising the Machine API capability gives a clear signal to the Red Hat created Machine API components that they should start the infrastructure generic controllers but not start a Machine controller.
- A partner wishes to add their own Cloud Controller Manager (CCM) written for their infrastructure. Setting the platform to "External" and advertising the CCM capability gives a clear to the Red Hat created CCM operator that the cluster should be configured for an external CCM that will be managed outside the operator. Although the Red Hat operator will not provide this functionality, it will configure the cluster to expect a CCM.
Acceptance Criteria
Phase 1
- Partners can read "External" platform enhancement and plan for their platform integrations.
- Teams can view jira cards for component changes and capability updates and plan their work as appropriate.
Phase 2
- Components running in cluster can detect the “External” platform through the Infrastructure config API
- Components running in cluster react to “External” platform as if it is “None” platform
- Partners can disable any of the platform specific components through the capabilities API
Phase 3
- Components running in cluster react to the “External” platform based on their function.
- for example, the Machine API Operator needs to run a set of controllers that are platform agnostic when running in platform “External” mode.
- the specific component reactions are difficult to predict currently, this criteria could change based on the output of phase 1.
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- Phase 1 requires talking with several component teams, the specific action that will be needed will depend on the needs of the specific component. At the least the components need to treat platform "External" as "None", but there could be more changes depending on the component (eg Machine API Operator running non-platform specific controllers).
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Empower External platform type user to specify when they will run their own CCM
Why is this important?
- For partners wishing to use components that require zonal awareness provided by the infrastructure (for example CSI drivers), they will need to exercise their own cloud controller managers. This epic is about adding the proper configuration to OpenShift to allow users of External platform types to run their own CCMs.
Scenarios
- As a Red Hat partner, I would like to deploy OpenShift with my own CSI driver. To do this I need my CCM deployed as well. Having a way to instruct OpenShift to expect an external CCM deployment would allow me to do this.
Acceptance Criteria
- CI - A new periodic test based on the External platform test would be ideal
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Update docs.ci.openshift.org with CCM docs
Dependencies (internal and external)
- ...
Previous Work (Optional):
- https://github.com/openshift/enhancements/blob/master/enhancements/cloud-integration/infrastructure-external-platform-type.md#api-extensions
- https://github.com/openshift/api/pull/1409
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
In the initial delivery of CoreOS Layering, it is required that administrators provide their own build environment to customize RHCOS images. That could be a traditional RHEL environment or potentially an enterprising administrator with some knowledge of OCP Builds could set theirs up on-cluster.
The primary virtue of an on-cluster build path is to continue using the cluster to manage the cluster. No external dependency, batteries-included.
MVP: bring the off-cluster build environment on-cluster
-
- Repo control
- rpm-ostree needs repo management commands
- Entitlement management
- Repo control
In the context of the Machine Config Operator (MCO) in Red Hat OpenShift, on-cluster builds refer to the process of building an OS image directly on the OpenShift cluster, rather than building them outside the cluster (such as on a local machine or continuous integration (CI) pipeline) and then making a configuration change so that the cluster uses them. By doing this, we enable cluster administrators to have more control over the contents and configuration of their clusters’ OS image through a familiar interface (MachineConfigs and in the future, Dockerfiles).
Feature Overview
Support Platform external to allow installing with agent on OCI, with focus on https://www.oracle.com/cloud/cloud-at-customer/dedicated-region/faq/ for disconnected, on-prem.
Related / parent feature
OCPSTRAT-510 OpenShift on Oracle Cloud Infrastructure (OCI) with VMs
Feature Overview
Support Platform external to allow installing with agent on OCI, with focus on https://www.oracle.com/cloud/cloud-at-customer/dedicated-region/faq/ for disconnected, on-prem
User Story:
As a user, I want to be able to:
- generate the minimal ISO in the installer when the platform type is set to external/oci
so that I can achieve
- successful cluster installation
- any custom agent features such as network tui should be available when booting from minimal ISO
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Review the OVN Interconnect proposal, figure out the work that needs to be done in ovn-kubernetes to be able to move to this new OVN architecture.
Phase-2 of this project in continuation of what was delivered in the earlier release.
Why is this important?
OVN IC will be the model used in Hypershift.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- ...
Why is this important?
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Create a Dynamic Plugin Template for custom metrics dashboard
- Created from RFE: https://issues.redhat.com/browse/RFE-2744
Why is this important?
- With OpenShift Container Platform 4.10, Dynamic Plugins went Tech Preview (https://docs.openshift.com/container-platform/4.10/release_notes/ocp-4-10-release-notes.html#ocp-4-10-dynamic-plugin-technology-preview) allowing to customize the web-console according to needs are requirements.
This is nice but requires a lot of effort on the customer to create such a plugin. It therefore would be nice to provide certain templates for such dynamic templates in order to help customers to get started. The templates could be for certain common use cases such as a page that allows viewing customer specific metric dashboards.
Similar what is available in the OpenShift 4 - Console under Observe with the dashboards but the ability to specify queries based on customer specific metrics and then define the type of the graph.
With the given template, it would be easier for customers to start adopting that functionality and continue building additional functionality if and where needed.
Scenarios
Dynamic Plugins is great but requires some effort to get started if somebody is not super familiar with the SDK made available. Therefore providing templates for certain use cases would be helpful for customers and even partners to increase knowledge faster and get started with the dynamic plugin functionality.
Currently there are three cases where the metrics are being displayed in the console:
- Standalone dashboard (e.g. Observe -> Dashboard)
- Simple Metrics dashboard tab (e.g. Pod Details > Metrics Dashboard)
- Highly customized dashboard (e.g. Home > Overview page)
For each of them we should have an example in the Metrics Template.
This document contains all the knowledge on the metrics use-cases and their requirements.
Visualising custom metrics is a common ask and therefore a potential good example to create such a template.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Add a graph component to the existing dynamic demo plugin that shows usage of the sdk
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Since `QueryBrowser` component was exposed in the console-dynamic-plugin-sdk we should showcase its usage.
One of the use cases should be to render a chart, using the `QueryBrowser` component, in a dashboard card. For the we would use the console.dashboard/card console extension.
AC:
- Update the dynamic-demo-plugin with the `console.dashboard/card` extension, where the QueryBrowser component will be used to render a chart. Part of the story is also to find a simple query that the `QueryBrowser` component will be fed with.
- Add cypress test for the chart.
As a cluster-admin I want to see conditional update path for releases on HCP. I want HCP to consume update recommendations from OpenShift Update Service (OSUS) similar to self-managed OCP clusters. And CVO of a hosted cluster should be able to evaluate conditional updates similar to self-managed OCP clusters.
Background.
Follow up from OTA-791{}
At a high level HCP updates should be handled by CVO and features like OSUS, conditional update should also be available in HCP. This Feature is a continuation of work OTA team is doing around CVO and HCP. **
Follow up from OTA-791
Epic Goal*
The Goal of this Epic is to:
- Enable the hosted control planes to consume update recommendations from OpenShift Update Service (OSUS) similar to self-managed OCP clusters.
- Enable the Cluster Version Operator (CVO) of a hosted cluster to evaluate conditional updates.
As part of the first phase, evaluation of conditional updates containing PromQL risks is implemented for self-managed HyperShift deployed on an OpenShift management cluster.
Why is this important? (mandatory)
What are the benefits to the customer or Red Hat? Does it improve security, performance, supportability, etc? Why is work a priority?
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Tests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Other
Once the CVO has configurable knobs for its PromQL engine (OTA-854), teach the hosted-control-plane operator's CVO controller to set those knobs to point them at the management-cluster's Thanos.
Definition of Done:
* teach the hosted-control-plane operator's CVO controller to set those knobs to point them at the management-cluster's Thanos.
HyperShift is considering allowing hosted clusters to avoid having a monitoring stack (ADR-30, OBSDA-242). Platform metrics for the hosted clusters contain the data we've used so far for conditional update risks, and those will be scraped by Prometheus on the management cluster, retained for >=24h, and remote-written to a Red Hat Observatorium cluster. Current conditional update risks have never gone beyond max_over_time(...[1h]) to smear over pod restarts and such, so local Prometheus/Thanos should have plenty of data for us.
This ticket is about adding knobs to the CVO so HyperShift can point it at that management-cluster Thanos.
Follow-up work will teach HyperShift to tune those knobs when creating the CVO deployment.
We need to enhance cluster network operator to automate the whole SDN live-migration.
- New API will be introduced to CNO to facilitate the migration
- CNO shall be able to deploy OVN-K and SDN in 'migration mode'
- CNO shall be able to annotate nodes to bypassing the IP allocation of OVN-K, when MCO is updating the MachineConfig of nodes
- CNO shall be able to redeploy the OVN-K and SDN in 'regular mode' after the migration is done.
During the migration, a node will start as an SDN node (a hybrid overlay node from OVN-K perspective), then become an OVN-K node. So OVN-K needs to support such dynamical role switching.
Task to track post-merge testing for this epic
Goal:
Enable and support Multus CNI for microshift.
Background:
Customers with advanced networking requirement need to be able to attach additional networks to a pod, e.g. for high-performance requirements using SR-IOV or complex VLAN setups etc.
Requirements:
- opt-in approach: customers can add multus if needed, e.g. by installing/adding "microshift-networking-multus" rpm package to their installation.
- if possible, it would be good to be able to add multus an existing installation. If that requires a restart/reboot, that is acceptable. If not possible, it has to be clearly documented.
- it is acceptable that once multus has been added to an installation, it can not be removed. If removal can be implemented easily, that would be good. If not possible, then it has to be clearly documented.
- Regarding additional networks:
- As part of the MVP, the Bridge plugin must be fully supported
- As stretch goal, macvlan and ipvlan plugins should be supported
- Other plugins, esp. host device and sr-iov are out of scope for the MVP, but will be added with a later version.
- Multiple additional networks need to be configurable, e.g. two different bridges leading to two different networks, each consumed by different pods.
- IP V6 with bridge plugin. Secondary NICs passed to a container via the bridge plugin should work with IP V6, if the consuming pod does support V6. See also "out of scope"
- Regarding IPAM CNI support for IP address provisioning, static and DHCP must be supported.
Documentation:
- In the existing "networking" book, we need a new chapter "4. Multiple networks". It can re-use a lot content from OCP doc "https://docs.openshift.com/container-platform/4.14/networking/multiple_networks/understanding-multiple-networks.html", but needs an extra chapter in the beginning "Installing support for multiple networks"{}
Testing:
- A simple "smoke test" that multus can be added, and a 2nd nic added to a pod (e.g. using host device) is sufficient. No need to replicate all the multus tests from OpenShift, as we assume that if it works there, it works with MicroShift.
Customer Considerations:
- This document contains the MVP requirements of a MicroShift EAP customer that need to be considered.
Out of scope:
- Other plugins, esp. host device and sr-iov are out of scope for the MVP, but will be added with a later version.
- IP V6 support with OVN-K. That is scope of feature OCPSTRAT-385
Epic Goal
- Provide optional Multus CNI for MicroShift
Why is this important?
- Customers need to add extra interfaces directly to Pods
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
- thin plugin
- only RHEL9
(contacting ART to setup image build is another task)
Feature Overview
- Customers want to create and manage OpenShift clusters using managed identities for Azure resources for authentication.
Goals
- A customer using ARO wants to spin up an OpenShift cluster with "az aro create" without needing additional input, i.e. without the need for an AD account or service principal credentials, and the identity used is never visible to the customer and cannot appear in the cluster.
- As an administrator, I want to deploy OpenShift 4 and run Operators on Azure using access controls (IAM roles) with temporary, limited privilege credentials.
Requirements
- Azure managed identities must work for installation with all install methods including IPI and UPI, work with upgrades, and day-to-day cluster lifecycle operations.
- Support HyperShift and non-HyperShift clusters.
- Support use of Operators with Azure managed identities.
- Support in all Azure regions where Azure managed identity is available. Note: Federated credentials is associated with Azure Managed Identity, and federated credentials is not available in all Azure regions.
More details at ARO managed identity scope and impact.
This Section: A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
References
- https://learn.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview
- https://docs.microsoft.com/en-us/azure/active-directory/develop/workload-identity-federation
- https://docs.microsoft.com/en-us/azure/active-directory/develop/workload-identities-overview
- https://learn.microsoft.com/en-us/azure/aks/workload-identity-overview
Epic Overview
- Enable customers to create and manage OpenShift clusters using managed identities for Azure resources for authentication.
- A customer using ARO wants to spin up an OpenShift cluster with "az aro create" without needing additional input, i.e. without the need for an AD account or service principal credentials, and the identity used is never visible to the customer and cannot appear in the cluster.
Epic Goal
- A customer creates an OpenShift cluster ("az aro create") using Azure managed identity.
- Azure managed identities must work for installation with all install methods including IPI and UPI, work with upgrades, and day-to-day cluster lifecycle operations.
- After Azure failed to implement workable golang API changes after deprecation of their old API, we have removed mint mode and work entirely in passthrough mode. Azure has plans to implement pod/workload identity similar to how they have been implemented in AWS and GCP, and when this feature is available, we should implement permissions similar to AWS/GCP
- This work cannot start until Azure have implemented this feature - as such, this Epic is a placeholder to track the effort when available.
Why is this important?
- Microsoft and the customer would prefer that we use Managed Identities vs. Service Principal (which requires putting the Service Principal and principal password in clear text within the azure.conf file).
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This document describes the expectations for promoting a feature that is behind a feature gate.
The criteria includes:
BU Priority Overview
Enable installation and lifecycle support of OpenShift 4 on Oracle Cloud Infrastructure (OCI) with VMs
Goals
- Enable installation of OpenShift 4 on Oracle Cloud Infrastructure (OCI) with VMs using platform agnostics with Assisted Installer.
- OpenShift 4 on OCI (with VMs) can be updated that results in a cluster and applications that are in a healthy state when update is completed.
- Telemetry reports back on clusters using OpenShift 4 on OCI for connected OpenShift clusters (e.g. platform=none using Oracle CSI).
State of the Business
Currently, we don't yet support OpenShift 4 on Oracle Cloud Infrastructure (OCI), and we know from initial attempts that installing OpenShift on OCI requires the use of a qcow (OpenStack qcow seems to work fine), networking and routing changes, storage issues, potential MTU and registry issues, etc.
Execution Plans
TBD based on customer demand.
Why is this important
- OCI is starting to gain momentum.
- In the Middle East (e.g. Saudi Arabia), only OCI and Alibaba Cloud are approved hyperscalars.
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
RFEs:
RFE-3635- Supporting Openshift on Oracle Cloud Infrastructure(OCI) & Oracle Private Cloud Appliance (PCA)
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
Other
Feature goal (what are we trying to solve here?)
Allow users to upload multi-document YAML files.
DoD (Definition of Done)
Users must be able to upload multi-document YAML files through the UI and API.
Does it need documentation support?
Yes, since users might not be aware they can use this method in order to upload many
Feature origin (who asked for this feature?)
- Internal request
Reasoning (why it’s important?)
- It turns out that the UI won't accept multi-document YAML files and there is a similar limitation in the back-end.
Feature usage (do we have numbers/data?)
- We have no data - the feature doesn’t exist anywhere
Feature availability (why should/shouldn't it live inside the UI/API?)
- This is an RFE for the custom manifests feature. We discovered at a later time that users can only upload one YAML file at a time, making this a tedious experience for those users needing to upload more than one or two files.
The BE API allows multi doc yamls to be uploaded as part of custom manifests, but it looks like openshift installer doesn't handle multi-doc yaml.
A solution could be to split the multi doc yaml file in several yaml files.
Feature Overview
Based on the work to enable OpenShift core platform components to support Azure Identity (captured in OCPBU-8), a standardized flow exists for OLM-managed operators to interact with the cluster in a specific way to leverage Azure Identity for authorization when using Azure APIs using short-lived tokens as opposed to insecure static, long-lived credentials. OLM-managed operators can implement integration with the CloudCredentialOperator in well-defined way to support this flow.
Goals:
Enable customers to easily leverage OpenShift's capabilities around Azure Identity for short-lived authentication tokens with layered products, for increased security posture. Enable OLM-managed operators to implement support for this in well-defined pattern.
Requirements:
- CCO gets a new mode in which it can reconcile Azure Workload Identity credential request for OLM-managed operators
- A standardized flow is leveraged to guide users in discovering and preparing their Azure IAM policies and roles with permissions that are required for OLM-managed operators
- A standardized flow is defined in which users can configure OLM-managed operators to leverage Azure Identity
- An example operator is used to demonstrate the end2end functionality
- Clear instructions and documentation for operator development teams to implement the required interaction with the CloudCredentialOperator to support this flow
Use Cases:
See Operators & STS slide deck. It refers to AWS STS as an example, but conceptually the same use case and workflow applies to Azure identity.
Out of Scope:
- handling OLM-managed operator updates in which Azure IAM permission requirements might change from one version to another (which requires user awareness and intervention)
Background:
The CloudCredentialsOperator already provides a powerful API for OpenShift's cluster core operator to request credentials and acquire them via short-lived tokens. This capability should be expanded to OLM-managed operators, specifically to Red Hat layered products that interact with Azure APIs. The process today is cumbersome to none-existent based on the operator in question and seen as an adoption blocker of OpenShift on Azure.
Customer Considerations
This is particularly important for ARO customers. Customers are expected to be asked to pre-create the required IAM roles outside of OpenShift, which is deemed acceptable.
Documentation Considerations
- Internal documentation needs to exists to guide Red Hat operator developer teams on the requirements and proposed implementation of integration with CCO and the proposed flow
- External documentation needs to exist to guide users on:
- how to become aware that the cluster is in Azure Identity mode
- how to become aware of operators that support Azure Identity and the proposed CCO flow
- how to become aware of the IAM permissions requirements of these operators
- how to configure an operator in the proposed flow to interact with CCO
Interoperability Considerations
- this needs to work with ARO
- this needs to work with self-managed OCP on Azure
See overview, goals, requirements, use cases, scope and background, etc as per https://issues.redhat.com/browse/OCPBU-560
Plan is to backport these changes to 4.14 so that they can be used on HCP / ROSA
Summary:
Similar to work done for AWS STS (https://issues.redhat.com/browse/CCO-286), enable in CCO a new workflow (see EP PR [here|https://github.com/openshift/enhancements/pull/1339)] to detect when temporary authentication tokens (TAT) (workload identity credential) are in use on a cluster. {{}}
Important details:
Detection that workload identity credentials (TAT) are in use will mean CCO is in Manual mode and the Service Account has a non-empty Service Account Issuer field.
This workflow will be triggered by additions to the CredentialsRequest for an operator:
spec.cloudTokenString
spec.cloudTokenPath
Acceptance Criteria:
When OCP is running on an Azure platform with temporary authentication tokens enabled, CCO will detect this and on the presence of properly annotated CredentialsRequest create a Secret to allow Azure SDK calls for Azure resources to succeed.
Feature Overview
Console enhancements based on customer RFEs that improve customer user experience.
Goals
- This Section:* Provide high-level goal statement, providing user context and expected user outcome(s) for this feature
- …
Requirements
- This Section:* A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
According to security best practice, it's recommended to set readOnlyRootFilesystem: true for all containers running on kubernetes. Given that openshift-console does not set that explicitly, it's requested that this is being evaluated and if possible set to readOnlyRootFilesystem: true or otherwise to readOnlyRootFilesystem: false with a potential explanation why the file-system needs to be write-able.
3. Why does the customer need this? (List the business requirements here)
Extensive security audits are run on OpenShift Container Platform 4 and are highlighting that many vendor specific container is missing to set readOnlyRootFilesystem: true or else justify why readOnlyRootFilesystem: false is set.
AC: Set up readOnlyRootFilesystem field on both console and console-operator deployment's spec. Part of the work is to determine the value. True if the pod if not doing any writing to its filesystem, otherwise false.
1. Proposed title of this feature request
Add option to enable/disable tailing to log viewer
2. What is the nature and description of the request?
See https://issues.redhat.com/browse/OCPBUGS-362
- prior to 4.10, on initial load, the log viewer loaded a maximum of the latest 1000 lines
- in 4.10, the 1000 line limit was removed per RFE requests (see https://github.com/openshift/console/pull/10486)
- multiple customers have requested the limit be returned, but this will revert the change to remove the limit per other RFE requests
- given the number of different configurable options on the log viewer, UX involvement to work through the interaction of adding the tail option is likely necessary
3. Why does the customer need this?
See https://issues.redhat.com/browse/OCPBUGS-362
4. List any affected packages or components.
Management Console
AC: Add functionality for tailing logs based on UX input. This functionality should be done for both Pod logs view. Add integration test.
UX draft - https://docs.google.com/document/u/2/d/1C9lO4JvUesAIn9U5m7Q98Tx4zw77sQGtzCJ4Wh6FAK0/edit?usp=sharing
UX contact - Tal Tobias
Show node uptime information in the Openshift Console.
When the user logs into the OpenShift web console and goes to the Nodes section, it doesn't display the uptime information of each node. Currently, it only shows the date when the node was created.
Customer wants to have additional info related to the time a node is up, i.e. since when the node is up, so it can be useful for tracking node restarts or failures.
Feature Overview (aka. Goal Summary)
Unify and update hosted control planes storage operators so that they have similar code patterns and can run properly in both standalone OCP and HyperShift's control plane.
Goals (aka. expected user outcomes)
- Simplify the operators with a unified code pattern
- Expose metrics from control-plane components
- Use proper RBACs in the guest cluster
- Scale the pods according to HostedControlPlane's AvailabilityPolicy
- Add proper node selector and pod affinity for mgmt cluster pods
Requirements (aka. Acceptance Criteria):
- OCP regression tests work in both standalone OCP and HyperShift
- Code in the operators looks the same
- Metrics from control-plane components are exposed
- Proper RBACs are used in the guest cluster
- Pods scale according to HostedControlPlane's AvailabilityPolicy
- Proper node selector and pod affinity is added for mgmt cluster pods
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal*
Our current design of EBS driver operator to support Hypershift does not scale well to other drivers. Existing design will lead to more code duplication between driver operators and possibility of errors.
Why is this important? (mandatory)
An improved design will allow more storage drivers and their operators to be added to hypershift without requiring significant changes in the code internals.
Scenarios (mandatory)
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Finally switch both CI and ART to the refactored aws-ebs-csi-driver-operator.
The functionality and behavior should be the same as the existing operator, however, the code is completely new. There could be some rough edges. See https://github.com/openshift/enhancements/blob/master/enhancements/storage/csi-driver-operator-merge.md
Ci should catch the most obvious errors, however, we need to test features that we do not have in CI. Like:
- custom CA bundles
- cluster-wide proxy
- custom encryption keys used in install-config.yaml
- government cluster
- STS
- SNO
- and other
Out CSI driver YAML files are mostly copy-paste from the initial CSI driver (AWS EBS?).
As OCP engineer, I want the YAML files to be generated, so we can keep consistency among the CSI drivers easily and make them less error-prone.
It should have no visible impact on the resulting operator behavior.
Goal
Guided installation user experience that interacts via prompts for necessary inputs, informs of erroneous/invalid inputs, and provides status and feedback throughout the installation workflow with very few steps, that works for disconnected, on-premises environments.
Installation is performed from a bootable image that doesn't contain cluster details or user details, since these details will be collected during the installation flow after booting the image in the target nodes.
This means that the image is generic and can be used to install an OpenShift cluster in any supported environment.
Why is this important?
Customers/partners desire a guided installation experience to deploy OpenShift with a UI that includes support for disconnected, on-premises environments, and which is as flexible in terms of configuration as UPI.
We have partners that need to provide an installation image that can be used to install new clusters on any location and for any users, since their business is to sell the hardware along with OpenShift, where OpenShift needs to be installable in the destination premises.
Acceptance Criteria
This experience should provide an experience closely matching the current hosted service (Assisted Installer), with the exception that it is limited to a single cluster because the host running the service will reboot and become a node in the cluster as part of the deployment process.
- User can successfully deploy OpenShift using the installer's guided experience.
- User can specify a custom registry for disconnected scenario, which may include uploading a cert and validation.
- User can specify node-network configurations, at a minimum: DHCP, Static IP, VLAN and Bonds.
- User can use the same image to install clusters with different settings (collected during the installation).
- Documentation is updated to guide user step-by-step to deploy OpenShift in disconnected settings with installer.
Dependencies
- Guided installation onboarding design from UXD team.
- UI development
Epic Goal
- Have a friendly graphical user to perform interactive installation that runs on node0
Why is this important?
- Allows the WebUI to run in Agent based installation where we can only count on node0 to run it
- Provides a familiar (close to SaaS) interface to walk through the first cluster installation
- Interactive installation takes us closer to having generated images that serve multiple first cluster installations
Scenarios
- As an admin, I want to generate an ISO that I can send to the field to perform a friendly, interactive installation
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- Assisted-Service WebUI needs an Agent based installation wizard
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Modify the cluster registration code in the assisted-service client (used by create-cluster-and-infraenv.service) to allow creating the cluster given only the following config manifests:
- ClusterImageSet
- InfraEnv
If the following manifests are present, data from them should be used:
- AgentPullSecret
- NMStateConfig
- extra manifests
Other manifests (ClusterDeployment, AgentClusterInstall) will not be present in an interactive install, and the information therein will be entered via the GUI instead.
A CLI flag or environment variable can be used to select the interactive mode.
create-cluster-and-infraenv.service will be split into agent-register-cluster.service and agent-register-infraenv.service.
Any existing systemd service dependency on create-cluster-and-infraenv.service should be moved to agent-register-infraenv.service.
Acceptance Criteria:
- Existing automated cluster installation flow should not be impacted.
- Update agent-gather to include these service logs
Feature Overview (aka. Goal Summary)
Upstream Kuberenetes is following other SIGs by moving it's intree cloud providers to an out of tree plugin format, Cloud Controller Manager, at some point in a future Kubernetes release. OpenShift needs to be ready to action this change
Goals (aka. expected user outcomes)
GA of the cloud controller manager for the GCP platform
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Background
To make the CCM GA, we need to update the switch case in library go to make sure the GCP CCM is always considered external.
We then need to update the vendor in KCMO, CCMO, KASO and MCO.
Steps
- Create a PR for updating library go
- Create PRs for updating the vendor in dependent repos
- Leverage an engineer with merge right (eg David Eads) to merge the library go, KCMO and CCMO changes simultaneously
- Merge KASO and MCO changes
Stakeholders
- Cluster Infra
Definition of Done
- GCP CCM is enabled by default
- Docs
- N/A
- Testing
- <Explain testing that will be added>
Goals
Track goals/requirements for self-managed GA of Hosted control planes on BM using the agent provider. Mainly make sure:
- BM flow via the Agent is documented.
- Make sure the documentation with HyperShiftDeployment is removed.
- Make sure the documentation uses the new flow without HyperShiftDeployment
- We have a reference architecture on the best way to deploy.
- UI for provisioning BM via MCE/ACM is complete (w host inventory).
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Background, and strategic fit
Customers are looking at HyperShift to deploy self-managed clusters on Baremetal. We have positioned the Agent flow as the way to get BM clusters due to its ease of use (it automates many of the rather mundane tasks required to setup up BM clusters) and its planned for GA with MCE 2.3 (in the OCP 4.13 timeframe).
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
To run a HyperShift management cluster in disconnected mode we need to document which images need to be mirrored and potentially modify the images we use for OLM catalogs.
ICSP mapping only happens for image references with a digest, not a regular tag. We need to address this for images we reference by tag:
CAPI, CAPI provider, OLM catalogs
Feature goal (what are we trying to solve here?)
Group all tasks for CAPI-provider-agent GA readiness
Does it need documentation support?
no
Feature origin (who asked for this feature?)
Internal request - Adel Zaalouk and Antoni Segura Puimedon
Reasoning (why it’s important?)
- In order for the Hypershift Agent platform to be GA in ACM 2.9 we need to improve our coverage and fix the bugs in this epic
Feature usage (do we have numbers/data?)
- We have no data - the feature doesn’t exist anywhere
Feature availability (why should/shouldn't it live inside the UI/API?)
- Please describe the reasoning behind why it should/shouldn't live inside the UI/API
- Does this feature exist in the UI of other installers?
Feature Overview (aka. Goal Summary)
Enable support to bring your own encryption key (BYOK) for OpenShift on IBM Cloud VPC.
Goals (aka. expected user outcomes)
As a user I want to be able to provide my own encryption key when deploying OpenShift on IBM Cloud VPC so the cluster infrastructure objects, VM instances and storage objects, can use that user-managed key to encrypt the information.
Requirements (aka. Acceptance Criteria):
The Installer will provide a mechanism to specify a user-managed key that will be used to encrypt the data on the virtual machines that are part of the OpenShift cluster as well as any other persistent storage managed by the platform via Storage Classes.
Background
This feature is a required component for IBM's OpenShift replatforming effort.
Documentation Considerations
The feature will be documented as usual to guide the user while using their own key to encrypt the data on the OpenShift cluster running on IBM Cloud VPC
Epic Goal*
Review and support the IBM engineering team while enabling BYOK support for OpenShift on IBM Cloud VPC
Why is this important? (mandatory)
As part of the replatform work IBM is doing for their OpenShift managed service this feature is Key for that work
Scenarios (mandatory)
All the cluster storage objects, VMs storage and storage managed by StorageClass objects defined in the platform., will be encrypted using the user-managed key provided in the installation manifest
Dependencies (internal and external) (mandatory)
https://issues.redhat.com/browse/CORS-2694
Contributing Teams(and contacts) (mandatory)
The IBM development team will be responsible of developing this feature and RH engineering team will review and support their work
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Epic Goal
- Review and support the IBM engineering team while enabling BYOK support for OpenShift on IBM Cloud VPC
Why is this important?
- As part of the replatform work IBM is doing for their OpenShift managed service this feature is Key for that work
Scenarios
- The installer will allow the user to provide their own key information to be used to encrypt the VMs storage and any storage object managed by OpenShift StorageClass objects
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a user, I am able to provide my own key for boot volume encryption when deploying OpenShift on IBM Cloud VPC.
Acceptance Criteria:
- User provides key in install config and proceeds with installation
- Boot volumes of control plane nodes are encrypted accordingly
Engineering Details:
Provide encryption key to infrastructure for provisioning of control plane nodes.
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Add support to the OpenShift Installer to specify a custom MTU to be used for the cluster network
Goals (aka. expected user outcomes)
As a user, I need to be able to provide a custom MTU to be consumed by the OpenShift Installer so I can change the cluster network MTU on day-0
Requirements (aka. Acceptance Criteria):
The OpenShift Installer will accept another parameter through the install-config manifest that will be used as an option to change the default MTU value for the cluster network
Use Cases (Optional):
Customers who are running OpenShift on environments where the network traffic between the cluster and external endpoints is limited to a certain MTU. Some examples are OpenShift clusters running on public clouds like AWS, Azure or GCP where these clusters are connected to external services running on the customer premises via direct links, VPNs, etc... and limited to a certain MTU
Background
Additional background can be found in RFE-4009
Documentation Considerations
As a new option will be added to the Installer manifest this will need to be documented as any other.
Epic Goal
- As a user, I need to be able to provide a custom MTU to be consumed by the OpenShift Installer so I can change the cluster network MTU on day-0
Why is this important?
- Customers who are running OpenShift on environments where the network traffic between the cluster and external endpoints is limited to a certain MTU. Some examples are OpenShift clusters running on public clouds like AWS, Azure or GCP where these clusters are connected to external services running on the customer premises via direct links, VPNs, etc... and limited to a certain MTU
Scenarios
- The OpenShift Installer will accept another parameter through the install-config manifest that will be used as an option to change the default MTU value for the cluster network
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Configure vSphere integration with credentials specified in the install-config.yaml file used by the agent install ISO image so that the platform integrations is configured on day-1 with the agent-based installer.
Stop ignoring any (optional) vSphere credential values provided in the install-config, and pass them instead to the cluster. This allows users to configure the credentials at day 1 if they want to, though it should remain optional. It also means that an install-config usable for IPI (where the credentials are required) should result in an equivalent cluster when the agent installer is used.
Currently there are warning messages logged about these values being ignored when provided. These warnings should be removed when the values are no longer ignored.
In the absence of direct API support for this in assisted, we should be able to use install-config overrides (which the agent installer is already able to make use of internally).
The json attribute name is named "user", but because the yaml.Marshal function is used, it fails to interpret that "user" defined in json is meant to represent the vSphere.vcenters.Username.
The fix is to change yaml.Marshal to json.Marshal in internal/installconfig/builder GetInstallConfig.
time="2023-09-25T21:29:07Z" level=error msg="error running openshift-install create manifests, stdout: level=warning msg=failed to parse first occurrence of unknown field: failed to unmarshal install-config.yaml: error unmarshaling JSON: while decoding JSON: json: unknown field \"username\"\nlevel=info msg=Attempting to unmarshal while ignoring unknown keys because strict unmarshaling failed\nlevel=error msg=failed to fetch Master Machines: failed to load asset \"Install Config\": failed to create install config: invalid \"install-config.yaml\" file: [platform.vsphere.vcenters.username: Required value: must specify the username, platform.vsphere.failureDomains.server: Invalid value: \"vcenterplaceholder\": server does not exist in vcenters]\n" func="github.com/openshift/assisted-service/internal/ignition.(*installerGenerator).runCreateCommand" file="/src/internal/ignition/ignition.go:1688" cluster_id=aad05e8e-a9fe-4f60-b580-0b2f6c4fdf10 error="exit status 3" go-id=1569 request_id= time="2023-09-25T21:29:07Z" level=error msg="failed generating install config for cluster aad05e8e-a9fe-4f60-b580-0b2f6c4fdf10" func="github.com/openshift/assisted-service/internal/bminventory.(*bareMetalInventory).generateClusterInstallConfig" file="/src/internal/bminventory/inventory.go:1755" cluster_id=aad05e8e-a9fe-4f60-b580-0b2f6c4fdf10 error="error running openshift-install manifests, level=warning msg=failed to parse first occurrence of unknown field: failed to unmarshal install-config.yaml: error unmarshaling JSON: while decoding JSON: json: unknown field \"username\"\nlevel=info msg=Attempting to unmarshal while ignoring unknown keys because strict unmarshaling failed\nlevel=error msg=failed to fetch Master Machines: failed to load asset \"Install Config\": failed to create install config: invalid \"install-config.yaml\" file: [platform.vsphere.vcenters.username: Required value: m <TRUNCATED>: exit status 3" go-id=1569 pkg=Inventory request_id=
The vSphere credentials needs to be passed through to assisted-service. The AgentConfigInstall ZTP manifests has an annotation where the install-config override can be set.
Acceptance Criteria:
- vSphere CSI network driver is installed when cluster is installed
Use any values provided in the install-config (e.g. root device hints, network config, BMC details) as defaults for the agent-config for the baremetal platform when installing with the agent-based installer.
If the agent-config file specifies host-specific settings then these should override the install-config. This enables users to use the same config for both agent-based and IPI installation.
If the user has an IPI install-config complete with BMC credentials, pass them through to the cluster so that it will end up with BareMetalHosts that can be managed by MAPI just as they would after an IPI install, instead of then having to add the credentials again on day 2.
BMC credentials must remain optional in the install-config though.
We allow the user to specify per-host settings (e.g. root device hints, network config) in the agent-config file, on any platform.
However, if the platform is baremetal, there is also fields for this data in the platform section of the install-config. Currently any data specified here is ignored (with a warning about this logged).
We should use any values provided in the install-config as defaults for the agent-config. If the agent-config specifies host-specific settings then these should override the install-config. This enables users to use the same config for both agent-based and IPI installation.
As part of this work, the logs warning of unused values should be removed.
If the install-config.yaml contains baremetal host configuration fields, and no host fields are defined in agent-config.yaml, use the install-config settings to define the hosts. The following fields will be copied over from the bm host definition
https://github.com/openshift/installer/blob/master/pkg/types/baremetal/platform.go#L37
- name -> hostname
- role -> role
- rootDeviceHints -> rootDeviceHints
- networkConfig -> networkConfig
The install-config struct does not have an interfaces field that matches agent-config, instead the bootMacAddress in install-config host will be used to create the interfaces array.
The hardwareProfile and bootMode fields will not be copied.
Add the name of the template to the infrastructure failure domain generated by the installer.
The OpenShift API needs to be updated to define VSphereFailureDomain. A draft PR is here: https://github.com/openshift/api/pull/1539
Also, ensure that the client-go and openshift-cluster-config-operator projects are bumped once the API changes merge.
nutanix is performing work in parallel and we need to pull out the common bits in to a non-vSphere specific PR
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
Why is this important? (mandatory)
What are the benefits to the customer or Red Hat? Does it improve security, performance, supportability, etc? Why is work a priority?
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
- https://github.com/openshift/cluster-kube-apiserver-operator/pull/1534
- https://github.com/openshift/cluster-kube-controller-manager-operator/pull/742
- https://github.com/openshift/cluster-kube-scheduler-operator/pull/490
- https://github.com/openshift/kubernetes/pull/1646
- https://github.com/openshift/origin/pull/28097
- https://github.com/openshift/origin/pull/28248
- https://github.com/openshift/origin/pull/28200
- https://github.com/openshift/origin/pull/28177
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned CAPI components should be running on Kubernetes 1.27
- target is 4.15 since CAPI is always a release behind upstream
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.15 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.27. This should be done by rebasing/updating as appropriate for the repository
Epic Goal
- Update all images that we ship with OpenShift to the latest upstream releases and libraries.
- Exact content of what needs to be updated will be determined as new images are released upstream, which is not known at the beginning of OCP development work. We don't know what new features will be included and should be tested and documented. Especially new CSI drivers releases may bring new, currently unknown features. We expect that the amount of work will be roughly the same as in the previous releases. Of course, QE or docs can reject an update if it's too close to deadline and/or looks too big.
Traditionally we did these updates as bugfixes, because we did them after the feature freeze (FF).
Why is this important?
- We want to ship the latest software that contains new features and bugfixes.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update all OCP and kubernetes libraries in storage operators to the appropriate version for OCP release.
This includes (but is not limited to):
- Kubernetes:
- client-go
- controller-runtime
- OCP:
- library-go
- openshift/api
- openshift/client-go
- operator-sdk
Operators:
- aws-ebs-csi-driver-operator (in csi-operator)
- aws-efs-csi-driver-operator
- azure-disk-csi-driver-operator
- azure-file-csi-driver-operator
- openstack-cinder-csi-driver-operator
- gcp-pd-csi-driver-operator
- gcp-filestore-csi-driver-operator
- csi-driver-manila-operator
- vmware-vsphere-csi-driver-operator
- alibaba-disk-csi-driver-operator
- ibm-vpc-block-csi-driver-operator
- csi-driver-shared-resource-operator
- ibm-powervs-block-csi-driver-operator
- secrets-store-csi-driver-operator
- cluster-storage-operator
- cluster-csi-snapshot-controller-operator
- local-storage-operator
- vsphere-problem-detector
EOL, do not upgrade:
- github.com/oVirt/csi-driver-operator
- https://github.com/openshift/alibaba-disk-csi-driver-operator/pull/72
- https://github.com/openshift/csi-operator/pull/71
- https://github.com/openshift/azure-disk-csi-driver-operator/pull/110
- https://github.com/openshift/azure-file-csi-driver-operator/pull/84
- https://github.com/openshift/cluster-csi-snapshot-controller-operator/pull/175
- https://github.com/openshift/cluster-storage-operator/pull/421
- https://github.com/openshift/csi-driver-manila-operator/pull/212
- https://github.com/openshift/csi-driver-shared-resource-operator/pull/92
- https://github.com/openshift/gcp-pd-csi-driver-operator/pull/97
- https://github.com/openshift/ibm-vpc-block-csi-driver-operator/pull/92
- https://github.com/openshift/openstack-cinder-csi-driver-operator/pull/143
- https://github.com/openshift/ibm-powervs-block-csi-driver-operator/pull/51
- https://github.com/openshift/vmware-vsphere-csi-driver-operator/pull/190
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update all CSI sidecars to the latest upstream release from https://github.com/orgs/kubernetes-csi/repositories
- external-attacher
- external-provisioner
- external-resizer
- external-snapshotter
- node-driver-registrar
- livenessprobe
Corresponding downstream repos have `csi-` prefix, e.g. github.com/openshift/csi-external-attacher.
This includes update of VolumeSnapshot CRDs in cluster-csi-snapshot-controller- operator assets and client API in go.mod. I.e. copy all snapshot CRDs from upstream to the operator assets + go get -u github.com/kubernetes-csi/external-snapshotter/client/v6 in the operator repo.
- https://github.com/openshift/csi-external-attacher/pull/58
- https://github.com/openshift/csi-external-provisioner/pull/70
- https://github.com/openshift/csi-external-resizer/pull/145
- https://github.com/openshift/csi-external-snapshotter/pull/107
- https://github.com/openshift/csi-livenessprobe/pull/48
- https://github.com/openshift/csi-node-driver-registrar/pull/50
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
(Using separate cards for each driver because these updates can be more complicated)
Update the driver to the latest upstream release. Notify QE and docs with any new features and important bugfixes that need testing or documentation.
This includes ibm-vpc-node-label-updater!
(Using separate cards for each driver because these updates can be more complicated)
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Cluster Infrastructure owned components should be running on Kubernetes 1.27
- This includes
- The cluster autoscaler (+operator)
- Machine API operator
- Machine API controllers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Machine API controllers for:
- Cloud Controller Manager Operator
- Cloud controller managers for:
- AWS
- Azure
- GCP
- vSphere
- OpenStack
- IBM
- Nutanix
- Cloud controller managers for:
- Cluster Machine Approver
- Cluster API Actuator Package
- Control Plane Machine Set Operator
Why is this important?
- ...
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- ...
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
To align with the 4.15 release, dependencies need to be updated to 1.28. This should be done by rebasing/updating as appropriate for the repository
Feature Overview (aka. Goal Summary)
Support OpenShift deployments on Azure to configure public and private exposure for OpenShift API and OpenShift Ingress separately at installation time
Goals (aka. expected user outcomes)
To reconcile the difference in publishing strategy the Installer provides on Azure vs what ARO offers. Upstream the capability to set split public and private API server and Ingress component.
Requirements (aka. Acceptance Criteria):
The user should be able to provide public or private publish configuration at installation time for the API and Ingress components.
Use Cases (Optional):
The initial use case will be for ARO customers as explained in ARO-2803
Background
ARO currently offers the ability to specify APIserver and ingress visibility at install time. You can set either to public or private, and they can differ (i.e. public ingress, private apiserver).
OpenShift currently does not have this feature natively, it must be done either day2 or via some other mechanism. Based on what you set the value of "publish" to in your install config (Internal | External) the components will or will not be internet accessible.
Documentation Considerations
This will require user facing documentation as any other option we currently document for OpenShift Installer
Feature Overview:
- Enablement of creation of a mix of public and private API servers and ingress configuration on Azure for improving access to the kubernetes cluster in certain circumstances
Goals:
- Allow for the users to create the new mix of public and private API servers and successfully resolve the URLs/IPs to access the cluster
Requirements:
- Users providing the setup they need in the install config
- URL resolution is still possible after the mix is installed
Use Cases:
- ARO needs this for a setup they have in mind.
https://issues.redhat.com/browse/ARO-2803
Questions to Answer:
- A spike is needed to figure out how this needs to be done
Out of Scope:
- ...
Background:
- ARO needs this for a setup they have in mind
Customer Considerations:
- Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status
Documentation Considerations:
- Docs for the install config and the architecture in general need to be done as the change is significant
Interoperability Considerations:
- Possibly the cluster ingress operator and the CAPI need to be checked if they need to be changed to accommodate this
User Story:
As a developer, I want to be able to:
- Allow for set the visibility of Ingress and API server.
so that I can
- Support ARO functionality of mix public private components in day 1.
Acceptance Criteria:
Description of criteria:
- ARO/users can set the visibility of ingress and API servers.
(optional) Out of Scope:
Engineering Details:
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Add support for the Installer to encrypt the Storage Account used for OpenShift on Azure at installation time.
Goals (aka. expected user outcomes)
As a user I can instruct the Installer to encrypt the Storage Account created while deploying OpenShift on Azure for increased security.
Requirements (aka. Acceptance Criteria):
The user is able to provide a Storage Account encryption ID to be used when the Installer creates the Storage Account for OpenShift on Azure.
Background
Related work on disks encryption for Azure was delivered as part of OCPSTRAT-308 feature. Now we are extending this to the Storage Account.
Documentation Considerations
Usual documentation will be required to explain how to use this option in the Installer
Implementation Considerations
Terraform is used for storage account creation
Feature Overview:
- Storage account on Azure needs to have the option to be encrypted for better security
Goals:
- Users should be able to encrypt the storage account
Requirements:
- SA encryption ID is accepted and used during terraform to encrypt the storage account (SA)
Use Cases:
- ...
Questions to Answer:
- ...
Out of Scope:
- Nothing
Background:
- A similar work for the disk encryption was done and needs to be extended for the storage accounts
- https://github.com/openshift/installer/pull/5641
Customer Considerations
- Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status
Documentation Considerations:
- Docs to accommodate the encryption needs to be done
Interoperability Considerations:
- Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status
User Story:
As a user, I want to be able to:
- Pass customer managed keys to the installer
so that
- The installer encrypts the storage accounts created
Acceptance Criteria:
Description of criteria:
- User is able to pass the neccesary information for encryption through the install config
- Storage account created for the control plane use is encrypted
(optional) Out of Scope:
Not encrypting the storage account used for bootstrap
Engineering Details:
- Encryption requires key vault id and user assigned identity keys mentioned here
https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/storage_account#customer_managed_key - Storage account must be set to `Premium` and kind to `StorageV2` which is default.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Goal
Hardware RAID support on Dell, Supermicro and HPE with Metal3.
Why is this important
Setting up RAID devices is a common operation in the hardware for OpenShift nodes. While there's been work at Fujitsu for configuring RAID in Fujitsu servers with Metal3, we don't support any generic interface with Redfish to extend this support and set it up it in Metal3.
Dell, Supermicro and HPE, which are the most common hardware platforms we find in our customers environments are the main target.
Goal
Hardware RAID support on Dell with Metal3.
Why is this important
Setting up RAID devices is a common operation in the hardware for OpenShift nodes. While there's been work at Fujitsu for configuring RAID in Fujitsu servers with Metal3, we don't support any generic interface with Redfish to extend this support and set it up it in Metal3 for Dell, which are the most common hardware platforms we find in our customers environments.
Before implementing generic support, we need to understand the implications of enabling an interface in Metal3 to allow it on multiple hardware types.
Scope questions
- Changes in Ironic?
- Maybe, but it should be there?
- Changes in Metal3?
- Hopefully small, it should be there for Fujitsu
- Changes in OpenShift?
- Hopefully small, it should be there for Fujitsu
- Spec/Design/Enhancements?
- Ironic: no (supports this already)
- Metal3: no (ditto)
- OpenShift:
https://github.com/openshift/enhancements/blob/master/enhancements/baremetal/baremetal-config-raid-and-bios.md
- Dependencies on other teams?
- No
While rendering BMO in https://issues.redhat.com/browse/METAL-829 the node cpu_arch was hardcoded to x86_64
We should use bmh.Spec.Architecture instead to be more future proof
Feature Overview
CoreOS Layering allows users to derive customized disk images for cluster nodes and update their nodes to these custom images. However, OpenShift still uses pristine images for the first boot of any machine. Customers should be allowed to use customized firstboot RHCOS images for machine installation.
This is critical to the needs of many OEMs and those working with cutting edge hardware with rapidly developing drivers.
Goals
- Allow customers to load out-of-tree device drivers required for RHCOS install. Usually NIC or storage drivers.
- It is OK for the initial phase to only apply to bare metal.
Investigate how we can enable customer to create their own boot images from a derived container.
One potential path is to work together with Image Builder team on what technology can be shared between our pipeline(s) and their building service.
Phase 1 focuses on building a RAW/QCOW2 FCOS/RHCOS disk image from a container image using osbuild and integrating with COSA / our pipeline.
In COSA when we create a disk image we stamp in a .coreos-aleph-version.json file that we then use for various other things later in time. We need an equivalent component when building disk images using OSBuild. Today the file is creating using this code:
cat > $rootfs/.coreos-aleph-version.json << EOF
{
"build": "${buildid}",
"ref": "${ref}",
"ostree-commit": "${commit}",
"imgid": "${imgid}"
}
EOF
We can feed some of this information into OSBuild via the manifest file but it might be really nice to be able to detect it dynamically from the installed tree so that we can reduce the requirements on future users of this having to know the values.
Another thing, I think since the `imgid` part here depends on what kind of image we are creating I think we might need to create a separate pipeline (i.e. `tree-qemu`) that adds in the correct imgid part, that is then fed into the qcow2 assembler. We probably also need to do something similar for `ignition.platform.id=qemu` in the future.
GitHub Internal PR: https://github.com/dustymabe/osbuild/pull/10
Upstream PR to OSBuild: https://github.com/osbuild/osbuild/pull/1475
Feature Overview (aka. Goal Summary)
Support AWS Wavelength Zones as a target infrastructure where to deploy OpenShift compute nodes.
Goals (aka. expected user outcomes)
As a user, I want to deploy OpenShift compute nodes on AWS Wavelength Zones at install time so I can leverage this infrastructure to deploy edge computing applications.
As a user, I want to extend an existing OpenShift cluster on AWS deploying compute nodes on AWS Wavelength Zones so I can leverage this infrastructure to deploy edge computing applications.
Requirements (aka. Acceptance Criteria):
The Installer will be able to deploy OpenShift on the public region into an existing VPC with compute nodes on AWS Wavelength Zones into an existing subnet.
The Installer will be able to deploy OpenShift on the public region with compute nodes on AWS Wavelength Zones automating the VPC creation in the public region and the subnet creation in the AWS Wavelength Zone
An existing OpenShift cluster on AWS public region can be extended by adding additional compute nodes (that can be automatically scaled) into AWS Wavelength Zones.
Use Cases (Optional):
Build media and entertainment applications.
Accelerate ML inference at the edge.
Develop connected vehicle applications.
Background
There is an extended demand for running specific workloads on edge locations on cloud providers. We have added support for AWS Outposts and AWS Local Zones. AWS Wavelength Zones is a demanded target infrastructure that customers are asking for including ROSA customers.
Documentation Considerations
Usual documentation will be required to instruct the user on how to use this feature
Epic Goal
- Support AWS Wavelength Zones as a target infrastructure where to deploy OpenShift compute nodes.
Why is this important?
- There is an extended demand for running specific workloads on edge locations on cloud providers. We have added support for AWS Outposts and AWS Local Zones. AWS Wavelength Zones is a demanded target infrastructure that customers are asking for including ROSA customers.
Scenarios
As a user, I want to deploy OpenShift compute nodes on AWS Wavelength Zones at install time in public subnets so I can leverage this infrastructure to deploy edge computing applications.
As a user, I want to deploy OpenShift compute nodes on AWS Wavelength Zones in public subnets in existing clusters installed with edge nodes so I can leverage this infrastructure to deploy edge computing applications.
Acceptance Criteria
- MAPI Provider AWS supports Carrier IP Address assignment to EC2 instances deployed by MachineSet definition in public subnets (with PublicIP==yes)
- Documentation with instructions provided on how to deploy machines in public subnets in AWS Wavelength Zones
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
USER STORY:
- As an developer, I would like to deploy ultra-low-latency sensitive applications in Wavelength Zones without needing an external load balancer to ingress traffic to edge nodes, so I can expand my application coverage using OCP
- As an OCP administrator, I would like to create machine sets to deploy instances in Wavelength Zones in public subnets using, so I can quickly develier nodes to developers deploy applications to that zones
- As an OCP developer, I would like to support MAPI to assign carrier public IP address when launching nodes in subnets in Wavelength Zones, so administrators can use the same interface as regular zone to extend worker nodes to edge zones.
Goal:
Wavelength Zones operates in Carrier Network, to ingress traffic to instances running into that zones, the Carrier IP Address must be assigned. The Carrier IP address is assigned to the instance when the network interface flag AssociateCarrierIpAddress must be set to when provisioning the instance.
The PublicIP is the existing flag available in the MachineSet to assign public IP address to node running in regular zone, the goal of this card is to teach MAPI AWS provider to look at the zone type for the subnet, and when the value is 'wavelength-zone' the flag AssociateCarrierIpAddress must be set to true, instead of the default AssociatePublicIpAddress, allowing EC2 service to assign public IP address in the carrier network.
Required:
- MAPI AWS provider must support public IP assignment by discovering the zone type without changing the API
ACCEPTANCE CRITERIA:
- MAPI AWS Provider PR must be created
- PR must be passing unit tests
- PR must be approved
ENGINEERING DETAILS:
- https://github.com/openshift/enhancements/pull/1510
- https://aws.amazon.com/wavelength/
- https://docs.aws.amazon.com/wavelength/latest/developerguide/how-wavelengths-work.html
Epic Goal
- Support AWS Wavelength Zones as a target infrastructure where to deploy OpenShift compute nodes in existing VPCs.
Why is this important?
- There is an extended demand for running specific workloads on edge locations on cloud providers. We have added support for AWS Outposts and AWS Local Zones. AWS Wavelength Zones is a demanded target infrastructure that customers are asking for including ROSA customers.
Scenarios
The Installer will be able to deploy OpenShift on the public region into an existing VPC with compute nodes on AWS Wavelength Zones into an existing subnet.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Support AWS Wavelength Zones as a target infrastructure where to deploy OpenShift compute nodes.
Why is this important?
- There is an extended demand for running specific workloads on edge locations on cloud providers. We have added support for AWS Outposts and AWS Local Zones. AWS Wavelength Zones is a demanded target infrastructure that customers are asking for including ROSA customers.
Scenarios
As a user, I want to deploy OpenShift compute nodes on AWS Wavelength Zones at install time so I can leverage this infrastructure to deploy edge computing applications.
The Installer will be able to deploy OpenShift on the public region with compute nodes on AWS Wavelength Zones automating the VPC creation in the public region and the subnet creation in the AWS Wavelength Zone
Acceptance Criteria
- PR reviewed and merged
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
USER STORY:
- As a cluster administrator, I want to deploy OpenShift compute nodes on AWS Wavelength Zones at install time, so I can leverage this infrastructure to deploy edge computing applications.
DESCRIPTION:
AWS Wavelength Zones are infrastructures running in RAN (Radio Access Network) owned by a Carrier, outside the region. AWS provides a few services, including computing, network ingress traffic in the carrier network, and private network connectivity with the VPC in the region.
The Installer must be able be able to deploy OpenShift worker nodes on the public region with compute nodes on AWS Wavelength Zones automating the VPC creation in the public region and the subnet creation in the AWS Wavelength Zone.
The installer must create the private and public subnet, and the worker node must use the private subnet.
In the traditional deployment for OpenShift on AWS, the private subnet egresss traffic to the internet using NAT Gateway. NAT Gateway is not currently supported in AWS Wavelength Zones. To remediate that, the deployment must follow the same strategy of associating the private subnets in Wavelength Zones to a route table in the region, preferably the route table for the WLZ's parent zone*.
*Every "edge zone" (Local and Wavelength Zone) is associated with one zone in the region, named the parent zone.
To ingress traffic to Wavelength Zone nodes, a public subnet must be created, and associated with a route table which have a carrier gateway as a default route. The carrier gateway is a similar internet gateway.
Required:
- installer change supporting Wavelength Zones created as an "edge" compute node
Nice to have:
...
{}ACCEPTANCE CRITERIA:{}
<!--
Describe the goals that need to be achieved so that this story can be
considered complete. Note this will also help QE to write their acceptance
tests.
-->
{}ENGINEERING DETAILS:{}
<!--
Any additional information that might be useful for engineers: related
repositories or pull requests, related email threads, GitHub issues or
other online discussions, how to set up any required accounts and/or
environments if applicable, and so on.
-->
Feature Overview (aka. Goal Summary)
An elevator pitch (value statement) that describes the Feature in a clear, concise way. Complete during New status.
Some OEM partners building RHDE platforms using MicroShift want to provide OLM to their customers with specially curated catalogs to allow end-user applications to depend on and install operators.
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Complete during New status.
- A user building a RHDE image should be able to specify that they want the image to include MicroShift, OLM, and their own catalog.
- It may need to be possible to build RHDE images without a catalog and install the catalog separately.
- Applications running on MicroShift should then be able to use OLM APIs to install and configure operators so the applications can use the operands.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
- A user building a RHDE image can install an RPM to cause OLM to be deployed on MicroShift using the automatic manifest loading feature of MicroShift.
- A user building a RHDE image for disconnected environments can embed all of the images needed to have OLM and their catalog of choice built into the RHDE image.
- OLM running on MicroShift should consume as little ressources as possible, targeting <100mcores, <100MB RAM
- Meta-Data needs to be added to the catalog to flag operators as supported on MicroShift
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
- It is not necessary as part of this work to curate the existing catalog of operators supported by Red Hat on OCP to produce a Red Hat edge catalog (we may do that work separately).
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. Initial completion during Refinement status.
Interoperability Considerations
Which other projects and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- Create a new optional RPM that automatically deploys the manifests
- update the rebase script to include OLM
- update the image list in the release RPM to include OLM images
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview
Extend OpenShift on IBM Cloud integration with additional features to pair the capabilities offered for this provider integration to the ones available in other cloud platforms.
Goals
Extend the existing features while deploying OpenShift on IBM Cloud.
Background, and strategic fit
This top level feature is going to be used as a placeholder for the IBM team who is working on new features for this integration in an effort to keep in sync their existing internal backlog with the corresponding Features/Epics in Red Hat's Jira.
Epic Goal
- Enable installation of disconnected clusters on IBM Cloud. This epic will track associated work.
Why is this important?
- Would like to support this at GA. It is an 'optional' feature that will be pursued after completing private cluster installation support ( https://issues.redhat.com/browse/SPLAT-731 ).
Scenarios
- Install a disconnected cluster on IBM Cloud.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
User Story:
A user currently is not able to create a Disconnected cluster, using IPI, on IBM Cloud.
Currently, support for BYON and Private clusters does exist on IBM Cloud, but support to override IBM Cloud Service endpoints does not exist, which is required to allow for Disconnected support to function (reach IBM Cloud private endpoints).
Description:
IBM Cloud VPC (x86_64) currently does not support Disconnected cluster installation via IPI.
In order to add this support, the override of certain IBM Cloud Services (e.g., IAM, IaaS), must be configurable and made available in the cluster infrastructure resource.
Implementation is dependent on API changes merging first (https://issues.redhat.com/browse/SPLAT-1097)
Acceptance Criteria:
Installer validates and injects user provided endpoint overrides into cluster deployment process.
User Story:
A user currently is not able to create a Disconnected cluster, using IPI, on IBM Cloud.
Currently, support for BYON and Private clusters does exist on IBM Cloud, but support to override IBM Cloud Service endpoints does not exist, which is required to allow for Disconnected support to function (reach IBM Cloud private endpoints).
Description:
IBM dependent components of OCP will need to add support to use a set of endpoint override values in order to reach IBM Cloud Services in Disconnected environments.
The MAPI component will need to be able to allow all API calls to IBM Cloud Services, be directed to these endpoint values, in order to communicate in environments where the Public or default IBM Cloud Service endpoint is not available.
The endpoint overrides are available via the infrastructure/cluster (.status.platformStatus.ibmcloud.serviceEndpoints) resource, which is how a majority of components are consuming cluster specific configurations (Ingress, MAPI, etc.). It will be structured as such
apiVersion: config.openshift.io/v1 kind: Infrastructure metadata: creationTimestamp: "2023-10-04T22:02:15Z" generation: 1 name: cluster resourceVersion: "430" uid: b923c3de-81fc-4a0e-9fdb-8c4c337fba08 spec: cloudConfig: key: config name: cloud-provider-config platformSpec: type: IBMCloud status: apiServerInternalURI: https://api-int.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 apiServerURL: https://api.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 controlPlaneTopology: HighlyAvailable cpuPartitioning: None etcdDiscoveryDomain: "" infrastructureName: us-east-disconnect-21-gtbwd infrastructureTopology: HighlyAvailable platform: IBMCloud platformStatus: ibmcloud: dnsInstanceCRN: 'crn:v1:bluemix:public:dns-svcs:global:a/fa4fd9fa0695c007d1fdcb69a982868c:f00ac00e-75c2-4774-a5da-44b2183e31f7::' location: us-east providerType: VPC resourceGroupName: us-east-disconnect-21-gtbwd serviceEndpoints: - name: iam url: https://private.us-east.iam.cloud.ibm.com - name: vpc url: https://us-east.private.iaas.cloud.ibm.com/v1 - name: resourcecontroller url: https://private.us-east.resource-controller.cloud.ibm.com - name: resourcemanager url: https://private.us-east.resource-controller.cloud.ibm.com - name: cis url: https://api.private.cis.cloud.ibm.com - name: dnsservices url: https://api.private.dns-svcs.cloud.ibm.com/v1 - name: cis url: https://s3.direct.us-east.cloud-object-storage.appdomain.cloud type: IBMCloud
The CCM is currently relying on updates to the openshift-cloud-controller-manager/cloud-conf configmap, in order to override its required IBM Cloud Service endpoints, such as:
data: config: |+ [global] version = 1.1.0 [kubernetes] config-file = "" [provider] accountID = ... clusterID = temp-disconnect-7m6rw cluster-default-provider = g2 region = eu-de g2Credentials = /etc/vpc/ibmcloud_api_key g2ResourceGroupName = temp-disconnect-7m6rw g2VpcName = temp-disconnect-7m6rw-vpc g2workerServiceAccountID = ... g2VpcSubnetNames = temp-disconnect-7m6rw-subnet-compute-eu-de-1,temp-disconnect-7m6rw-subnet-compute-eu-de-2,temp-disconnect-7m6rw-subnet-compute-eu-de-3,temp-disconnect-7m6rw-subnet-control-plane-eu-de-1,temp-disconnect-7m6rw-subnet-control-plane-eu-de-2,temp-disconnect-7m6rw-subnet-control-plane-eu-de-3 iamEndpointOverride = https://private.iam.cloud.ibm.com g2EndpointOverride = https://eu-de.private.iaas.cloud.ibm.com rmEndpointOverride = https://private.resource-controller.cloud.ibm.com
These changes have already landed in the release-1.28 branch (target OCP release-4.15 branch), but we need to make sure they get pulled into the github.com/openshift/cloud-provider-ibm branch and built into a 4.15 image.
Acceptance Criteria:
Installer validates and injects user provided endpoint overrides into cluster deployment process and the MAPI components use specified endpoints and start up properly.
User Story:
A user currently is not able to create a Disconnected cluster, using IPI, on IBM Cloud.
Currently, support for BYON and Private clusters does exist on IBM Cloud, but support to override IBM Cloud Service endpoints does not exist, which is required to allow for Disconnected support to function (reach IBM Cloud private endpoints).
Description:
IBM dependent components of OCP will need to add support to use a set of endpoint override values in order to reach IBM Cloud Services in Disconnected environments.
The Storage components will need to be able to allow all API calls to IBM Cloud Services, be directed to these endpoint values, in order to communicate in environments where the Public or default IBM Cloud Service endpoint is not available.
The endpoint overrides are available via the infrastructure/cluster (.status.platformStatus.ibmcloud.serviceEndpoints) resource, which is how a majority of components are consuming cluster specific configurations (Ingress, MAPI, etc.). It will be structured as such
apiVersion: config.openshift.io/v1 kind: Infrastructure metadata: creationTimestamp: "2023-10-04T22:02:15Z" generation: 1 name: cluster resourceVersion: "430" uid: b923c3de-81fc-4a0e-9fdb-8c4c337fba08 spec: cloudConfig: key: config name: cloud-provider-config platformSpec: type: IBMCloud status: apiServerInternalURI: https://api-int.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 apiServerURL: https://api.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 controlPlaneTopology: HighlyAvailable cpuPartitioning: None etcdDiscoveryDomain: "" infrastructureName: us-east-disconnect-21-gtbwd infrastructureTopology: HighlyAvailable platform: IBMCloud platformStatus: ibmcloud: dnsInstanceCRN: 'crn:v1:bluemix:public:dns-svcs:global:a/fa4fd9fa0695c007d1fdcb69a982868c:f00ac00e-75c2-4774-a5da-44b2183e31f7::' location: us-east providerType: VPC resourceGroupName: us-east-disconnect-21-gtbwd serviceEndpoints: - name: iam url: https://private.us-east.iam.cloud.ibm.com - name: vpc url: https://us-east.private.iaas.cloud.ibm.com/v1 - name: resourcecontroller url: https://private.us-east.resource-controller.cloud.ibm.com - name: resourcemanager url: https://private.us-east.resource-controller.cloud.ibm.com - name: cis url: https://api.private.cis.cloud.ibm.com - name: dnsservices url: https://api.private.dns-svcs.cloud.ibm.com/v1 - name: cis url: https://s3.direct.us-east.cloud-object-storage.appdomain.cloud type: IBMCloud
The CCM is currently relying on updates to the openshift-cloud-controller-manager/cloud-conf configmap, in order to override its required IBM Cloud Service endpoints, such as:
data: config: |+ [global] version = 1.1.0 [kubernetes] config-file = "" [provider] accountID = ... clusterID = temp-disconnect-7m6rw cluster-default-provider = g2 region = eu-de g2Credentials = /etc/vpc/ibmcloud_api_key g2ResourceGroupName = temp-disconnect-7m6rw g2VpcName = temp-disconnect-7m6rw-vpc g2workerServiceAccountID = ... g2VpcSubnetNames = temp-disconnect-7m6rw-subnet-compute-eu-de-1,temp-disconnect-7m6rw-subnet-compute-eu-de-2,temp-disconnect-7m6rw-subnet-compute-eu-de-3,temp-disconnect-7m6rw-subnet-control-plane-eu-de-1,temp-disconnect-7m6rw-subnet-control-plane-eu-de-2,temp-disconnect-7m6rw-subnet-control-plane-eu-de-3 iamEndpointOverride = https://private.iam.cloud.ibm.com g2EndpointOverride = https://eu-de.private.iaas.cloud.ibm.com rmEndpointOverride = https://private.resource-controller.cloud.ibm.com
The Storage component is reliant on the CCM cloud-conf configmap, but only the IAM, ResourceManager, and VPC endpoints are supplied, since that is all CCM uses. If additional IBM Cloud Services are used (e.g., COS, etc.), they will not be available in the CCM cloud-conf, but will always be in the infrastructure/cluster resource.
Acceptance Criteria:
Installer validates and injects user provided endpoint overrides into cluster deployment process and the storage components use specified endpoints and start up properly.
User Story:
A user currently is not able to create a Disconnected cluster, using IPI, on IBM Cloud.
Currently, support for BYON and Private clusters does exist on IBM Cloud, but support to override IBM Cloud Service endpoints does not exist, which is required to allow for Disconnected support to function (reach IBM Cloud private endpoints).
Description:
IBM dependent components of OCP will need to add support to use a set of endpoint override values in order to reach IBM Cloud Services in Disconnected environments.
The Ingress Operator components will need to be able to allow all API calls to IBM Cloud Services, be directed to these endpoint values, in order to communicate in environments where the Public or default IBM Cloud Service endpoint is not available.
The endpoint overrides are available via the infrastructure/cluster (.status.platformStatus.ibmcloud.serviceEndpoints) resource, which is how a majority of components are consuming cluster specific configurations (Ingress, MAPI, etc.). It will be structured as such
apiVersion: config.openshift.io/v1 kind: Infrastructure metadata: creationTimestamp: "2023-10-04T22:02:15Z" generation: 1 name: cluster resourceVersion: "430" uid: b923c3de-81fc-4a0e-9fdb-8c4c337fba08 spec: cloudConfig: key: config name: cloud-provider-config platformSpec: type: IBMCloud status: apiServerInternalURI: https://api-int.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 apiServerURL: https://api.us-east-disconnect-21.ipi-cjschaef-dns.com:6443 controlPlaneTopology: HighlyAvailable cpuPartitioning: None etcdDiscoveryDomain: "" infrastructureName: us-east-disconnect-21-gtbwd infrastructureTopology: HighlyAvailable platform: IBMCloud platformStatus: ibmcloud: dnsInstanceCRN: 'crn:v1:bluemix:public:dns-svcs:global:a/fa4fd9fa0695c007d1fdcb69a982868c:f00ac00e-75c2-4774-a5da-44b2183e31f7::' location: us-east providerType: VPC resourceGroupName: us-east-disconnect-21-gtbwd serviceEndpoints: - name: iam url: https://private.us-east.iam.cloud.ibm.com - name: vpc url: https://us-east.private.iaas.cloud.ibm.com/v1 - name: resourcecontroller url: https://private.us-east.resource-controller.cloud.ibm.com - name: resourcemanager url: https://private.us-east.resource-controller.cloud.ibm.com - name: cis url: https://api.private.cis.cloud.ibm.com - name: dnsservices url: https://api.private.dns-svcs.cloud.ibm.com/v1 - name: cis url: https://s3.direct.us-east.cloud-object-storage.appdomain.cloud type: IBMCloud
The CCM is currently relying on updates to the openshift-cloud-controller-manager/cloud-conf configmap, in order to override its required IBM Cloud Service endpoints, such as:
data: config: |+ [global] version = 1.1.0 [kubernetes] config-file = "" [provider] accountID = ... clusterID = temp-disconnect-7m6rw cluster-default-provider = g2 region = eu-de g2Credentials = /etc/vpc/ibmcloud_api_key g2ResourceGroupName = temp-disconnect-7m6rw g2VpcName = temp-disconnect-7m6rw-vpc g2workerServiceAccountID = ... g2VpcSubnetNames = temp-disconnect-7m6rw-subnet-compute-eu-de-1,temp-disconnect-7m6rw-subnet-compute-eu-de-2,temp-disconnect-7m6rw-subnet-compute-eu-de-3,temp-disconnect-7m6rw-subnet-control-plane-eu-de-1,temp-disconnect-7m6rw-subnet-control-plane-eu-de-2,temp-disconnect-7m6rw-subnet-control-plane-eu-de-3 iamEndpointOverride = https://private.iam.cloud.ibm.com g2EndpointOverride = https://eu-de.private.iaas.cloud.ibm.com rmEndpointOverride = https://private.resource-controller.cloud.ibm.com
Acceptance Criteria:
Installer validates and injects user provided endpoint overrides into cluster deployment process and the Ingress Operator components use specified endpoints and start up properly.
We have a blocking issue that is fixed and included in IBM TF Provider release 1.60.0. We need this pulled into OCP 4.15.
IBM PowerVS has been notified.
Feature Overview (aka. Goal Summary)
Add support for il-central-1 in AWS
Goals (aka. expected user outcomes)
As a user I'm able to deploy OpenShift in il-central-1 in AWS and this region is fully supported
Requirements (aka. Acceptance Criteria):
A user can deploy OpenShift in AWS il-central-1 using all the supported installation tools for self-managed customers.
The support of this region is backported to the previous OpenShift EUS release.
The corresponding RHCOS image needs to be available in the new region so the Installer can list the region.
Background
AWS has added support for a new region in their public cloud offering and this region needs to be supported for OpenShift deployments as other regions.
Documentation Considerations
The information about the new region needs to be added to the documentation so this is supported.
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
MVP aims at refactoring MirrorToDisk and DiskToMirror for OCP releases
- Execute command line
- Copy & untar release-index
- Inspect untarred folder
- gather release images from disk
- Generate artifacts (icsp)
- bulk pull-push payload images
- gather release-index
- unit test & e2e
As an MVP, this epic covers the work for RFE-3800 (includes RFE-3393 and RFE-3733) for mirroring releases.
The full description / overview of the enclave support is best described here
The design document can be found here
Upcoming epics, such as CFE-942 will complete the RFE work with mirroring operators, additionalImages, etc.
Architecture Overview (diagram)
- Acceptance Criteria
- All unit tests pass (80% coverage)
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
- Tasks
- Implement V2 versioning as discussed in the EP document
- Update cli to switch to v2 and use new cli parameters
- Hide the logs of the local storage registry in a different file
- Add a flag to the CLI to choose the port for the local storage registry
- Implement code for new cli (Executor) and relevant flags
- Implement unit tests
oc-mirror v1 and v2 can cohabitate.
by default, v1 code is called.
oc-mirror switches to the use of the v2 when a certain flag is added
logs from the local storage registry of oc-mirror need to be redirected in another log file
As a oc-mirror user, I want the tar generated by mirror to disk process to be as small as possible so that its transfer to the enclaves is as quick as possible.
Background:
After the first demo done by the team, the initial solution that consisted of archiving the whole cache and sending it through the one-way diode to the enclaves was refused by the stakeholders.
CFE-966 studied a solution to include in the tar:
- only new images
- only new blobs and manifests
This story is about implementing the studied solution.
Acceptance criteria:
- Scenario 1: mirroring additional images - No previous history
- Create a first mirroring with additionalImage:
quay.io/okd/scos-release:4.14.0-0.okd-scos-2023-10-19-123226 - MirrorToDisk should be successful
- The tar.gz should be available under working-dir
- the DiskToMirror based on the above generated tar.gz should be successful
- The destination registry should have this image, and I should be able to inspect it using skopeo inspect
- Create a first mirroring with additionalImage:
- Scenario 2: mirroring additional images - with previous history
- Create a second mirroring with additionalImage:
quay.io/okd/scos-release:4.14.0-0.okd-scos-2023-10-19-111256- This can be with the same imageSetConfig of scenario1, to which we append this image
- MirrorToDisk should be successful
- The tar.gz should be available under working-dir
- The tar.gz should not contain blobs 97da74cc6d8fa5d1634eb1760fd1da5c6048619c264c23e62d75f3bf6b8ef5c4 nor d8190195889efb5333eeec18af9b6c82313edd4db62989bd3a357caca4f13f0e (previously mirrored)
- The size of the tar.gz should be smaller than the first tar.gz
- the DiskToMirror based on the above generated tar.gz should be successful
- The destination registry should have this new image, and I should be able to inspect it using skopeo inspect it by tag
- Create a second mirroring with additionalImage:
I need an implementation (and interface) that constructs a tar.gz from:
- the contents of working-dir (excluding existing tars)
- the repositories folder from the cache's localstorage
- all blobs listed in the list that the function gets from the input
- the imagesetconfig
Tar contents:
- docker/v2/repositories : manifests for all mirrored images
- docker/v2/blobs/sha256 : blobs that haven't been mirrored (diff)
- working-dir
- image set config
Diff logic:
I need an implementation (and interface) that can be used at the beginning of the diskToMirror process (!!!! before starting the local cache) and that would extract each part of the tar.gz to its location:
- docker/v2/repositories => local registry cache storage
- docker/v2/blobs/sha256 => local registry cache storage
- working-dir => working-dir folder
- hidden history file => under working-dir
- image set config => under wokring-dir
Definitions:
- cache-dir: path to the folder containing docker/v2/repositories.. and that can be used by the local cache (local registry) of oc-mirror
- working-dir: path to the folder containing custom resources (IDMS, ITMS, catalogSource, etc), history metadata, archives, some catalog and release manifests .
Requirement
AS the admin of several clusters of my company, with several enclaves involved,
WHEN doing MirrorToDisk for several enclaves
I would like to be able to reuse the cache-dir of my main environement (entreprise level) for all enclaves,
AND use a separate working-dir for each enclave
SO THAT I can gain in storage volume and in performance, while preserving a separate context for each enclave
- Stop registry
- call blobGatherer on all collected images
- call archiver to generate the archive
Check how to enable signature verification using the skopeo mod (copy method)
When graph: true is specified for releases in the imageSetConfig, I'd like oc-mirror to create and mirror a graph image for ocp releases
- Acceptance Criteria
- All tests pass (80%) coverage
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
- Tasks
- Implement V2 versioning as discussed in the EP document
- Implement code to generate artifacts IDMS ITMS and audit data
- Implement unit tests
In order to keep the same behavior as v1, we need to have the mirroring at the namespace level
- Acceptance Criteria
- All tests pass (80%) coverage
- Documentation approved by docs team
- All tests QE approved
- Well documented README/HOWTO/OpenShift documentation
- Tasks
- Implement V2 versioning as discussed in the EP document
- Implement code to bulk (use concurrency) push-pull release images
- Implement unit tests
Feature Overview (aka. Goal Summary)
As an openshift admin i want to prevent must-gather to fill the disk space as must-gather runs in master node so that if it fills up disk then it can cause problem in master node thus can affecting the stability of the my OCP env
Goals (aka. expected user outcomes)
The observable functionality that the user now has as a result of receiving this feature. Complete during New status.
Define configurable default limit to emptydir volume in must gather pod
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- ...
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
This card is about:
- making 4.13 -> 4.14 upgrade compulsory, that is we shouldn't allow an upgrade from a version < 4.14 to a version > 4.14. in order to ensure that the IC upgrade logic on 4.14 is executed.
- removing in CNO 4.15 all the code related to the non-IC to IC upgrade: the logic itself in ovn_kubernetes.go, the operator status hack in pod_status.go, the yamls in the single-zone folder and the yamls (which are mostly symlinks) in the multizone-tmp folder.
Template:
Networking Definition of Planned
Epic Template descriptions and documentation
Epic Goal
With ovn-ic we have multiple actors (zones) setting status on some CRs. We need to make sure individual zone statuses are reported and then optionally merged to a single status
Why is this important?
Without that change zones will overwrite each others statuses.
Planning Done Checklist
The following items must be completed on the Epic prior to moving the Epic from Planning to the ToDo status
 Priority+ is set by engineering
Priority+ is set by engineering- Epic must be Linked to a +Parent Feature
 Target version+ must be set
Target version+ must be set- Assignee+ must be set
- (Enhancement Proposal is Implementable
- (No outstanding questions about major work breakdown
- (Are all Stakeholders known? Have they all been notified about this item?
- Does this epic affect SD? {}Have they been notified{+}? (View plan definition for current suggested assignee)
- Please use the “Discussion Needed: Service Delivery Architecture Overview” checkbox to facilitate the conversation with SD Architects. The SD architecture team monitors this checkbox which should then spur the conversation between SD and epic stakeholders. Once the conversation has occurred, uncheck the “Discussion Needed: Service Delivery Architecture Overview” checkbox and record the outcome of the discussion in the epic description here.
- The guidance here is that unless it is very clear that your epic doesn’t have any managed services impact, default to use the Discussion Needed checkbox to facilitate that conversation.
Additional information on each of the above items can be found here: Networking Definition of Planned
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement
details and documents.
...
Dependencies (internal and external)
1.
...
Previous Work (Optional):
1. …
Open questions::
1. …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
The MCO merges MachineConfigs in alphanumerical order. Because all custom pools also are workers, this effectively means that all "worker" configs will take precedence over custom pools that come earlier in alphabetic order. This is counter to most expectations where the reason for creating the custom pool is in order to be different than the worker pool.
Goals (aka. expected user outcomes)
Custom pool configs will "win" over worker configs. This is inline with what most customers expect.
[original description related to a specific scenario that this more general feature will help facilitate. It's been moved to comments]
User story
As an OpenShift admin with custom pools,
I would like my custom pool configuration, especially those generated by the MCO (kubelet, containerruntime, node config, etc.) to take priority over base worker pool configs
So I can have custom configs for custom pool take effect.
This is a behaviour change and should also be noted as such in docs/release notes.
Follow up cards were moved to https://issues.redhat.com/browse/MCO-773
Due to alphanumeric ordering of the MCs, MCC-generated configs with pool names will get ordered such that worker configuration will generally take priority over custom pools, unless the custom pool name started with x,y,or z.
This is mostly a problem for kubelet and containerruntimeconfigs. If the user wanted to create a kubeletconfig for base workers and then a special one for the custom pool, they are unable do easily do so.
We should assume the user wants custom configs to take priority since all base worker configuration is otherwise inherited. Thus our MC merging logic should be updated to handle this.
Feature Overview (aka. Goal Summary)
OLM users can stay on the supported path for an installed operator package by
- seeing if an installed operator package is:
- deprecated entirely,
- currently subscribed to a deprecated channel, or
- currently stays in a deprecated version, and
- also knowing the alternative package or update channel(s) to change to, if provided by the operator authors/package maintainers.
Goals (aka. expected user outcomes)
- Operator package maintainers can mark the entire package, an update channel, or an individual bundle version as deprecated and optionally provide a suggested package, update channel(s), or version(s) for the ongoing update path(s).
- OLM users can see the deprecation marker/indicator from CLI (and UI in the future) and are discouraged from installing a deprecated package or from deprecated channels. → pre-installation
- OLM users can see the deprecation marker/indicator from CLI (and UI in the future) to tell if an installed operator is deprecated entirely or is currently subscribed to a deprecated channel, and they know the alternative package or update channel(s) to stay on the supported path → post-installation
- Cluster or operator admins can get an aggregated report with another tooling from the deprecation marker/indicator to know centrally from their cluster fleets if any operator package installed was deprecated and out of support.
Requirements (aka. Acceptance Criteria):
Operator package maintainers can denote deprecation information in file-based catalogs via the catalog templates:the entire package as “deprecated” and optionally provide recommended package(s) with a short description as the alternative in file-based catalogs (e.g., in olm.package) via the catalog templates.an update channel as “deprecated” and optionally provide recommended channel(s) with a short description as the alternative in file-based catalogs (e.g., in olm.channel) via the catalog templates.a specific version as “deprecated” and optionally provide recommended version(s) with a short description as the alternative in file-based catalogs (e.g., via olm.bundle) via the catalog templates.
- Operator package maintainers can denote deprecation information in file-based catalogs via the bundle-based workflow using the current Red Hat build pipeline:
- the entire package as “deprecated” and optionally provide recommended package(s) with a short description as the alternative in file-based catalogs (e.g., in olm.package) via the bundle-based workflow using the current Red Hat build pipeline.
- an update channel as “deprecated” and optionally provide recommended channel(s) with a short description as the alternative in file-based catalogs (e.g., in olm.channel) via the bundle-based workflow using the current Red Hat build pipeline.
- a specific version as “deprecated” and optionally provide recommended version(s) with a short description as the alternative in file-based catalogs (e.g., via olm.bundle) via the bundle-based workflow using the current Red Hat build pipeline.
- OLM Package Server can serve the “deprecated” information and the optional recommended alternative with a short description of the packages in a catalog.
- A user can get the “deprecated” information via CLI or UI to interact with the OLM Package Server. → Pre-installation.
- OLM Subscription can serve the “deprecated” information and the optional recommended alternative with a short description of the packages in a catalog.
- A user can get the “deprecated” information via CLI or UI that interacts with the OLM Subscription. → Post-installation.
- OLM exposes the “deprecated” information of a particular operator (i.e., it’s “deprecated entirely” or “subscribing to a deprecated channel”) such that an external tool, such as ACM, can display a report to show “how many deprecated operators" from this particular cluster”, or “how many deprecated operators from the cluster fleet”.
- Notes:
- option 1) separated Prometheus metrics to indicate if a package, update channel, or version is deprecated in the cluster.
- option 2) A note (from the ACM team on Aug 4th):
- "ACM can query arbitrary object types with some saved searches"
- Scott Berens: We from the xCM (ACM) Search side, are in full support.
- "ACM can query arbitrary object types with some saved searches"
- Notes:
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
We have customers (e.g., Citigroup) who have dozens of operators installed in hundreds of clusters. They need to conduct audits periodically to tell if all the installed operators are still within the support boundary. Currently, there’s no way for them to tell if a particular operator package, or an update channel being subscribed to, or a current running operator version is supported or not.
OLM extends the support in content deprecation management will enable operator package maintainers to curate this type of information better and benefits the admin types of users of our product.
Customer Considerations
- Citigroup
- Red Hat Operators/Layered products
Documentation Considerations
Operator package maintainers need to know how to denote:the entire package as “deprecated” and optionally provide recommended package(s) with a short description as the alternative in file-based catalogs via the catalog templates.an update channel as “deprecated” and optionally provide recommended channel(s) with a short description as the alternative in file-based catalogs via the catalog templates.a specific version as “deprecated” (if not executing a “minor version channel” scheme) and optionally provide recommended version(s) with a short description as the alternative in file-based catalogs via the catalog templates.
- Red Hat internal operator package maintainers need to know how to denote:
- the entire package as “deprecated” and optionally provide recommended package(s) with a short description as the alternative in file-based catalogs via the bundle-based workflow using the current Red Hat build pipeline.
- an update channel as “deprecated” and optionally provide recommended channel(s) with a short description as the alternative in file-based catalogs via the bundle-based workflow using the current Red Hat build pipeline.
- a specific version as “deprecated” and optionally provide recommended version(s) with a short description as the alternative in file-based catalogs via the bundle-based workflow using the current Red Hat build pipeline
- (Pre-installation) OLM CLI users (cluster-admin or an admin-type persona) need to know how to query OLM Package Server to see:
- i) if an operator package is deprecated entirely or is currently subscribed to a deprecated channel
- ii) the recommended alternative to the depreciated content with a short description.
- (Post-installation) OLM CLI users (cluster-admin or an admin-type persona) need to know to use OLM Subscription API to see:
- i) if an operator package is deprecated entirely or is currently subscribed to a deprecated channel
- ii) the recommended alternative to the depreciated content with a short description.
- Admin-type users need to know how to generate an aggregated report with another tooling from the deprecation marker/indicator to know centrally from their cluster fleets if any operator package installed was deprecated and out of support.
- [Need Console support] OLM/OCP console users (cluster-admin or an admin type of persona) need to know if an installed operator package is deprecated entirely, is currently subscribed to a deprecated channel, or currently stays in a deprecated version.
Interoperability Considerations
- With Red Hat build pipeline for Red Hat internal operator package maintainers.
- With OLM v0 with the supported target OpenShift version.
As per #1146
GRPC API (pkg/api/*; pkg/registry/types.go; utests)
Upstream Github issue: https://github.com/operator-framework/operator-registry/issues/1154
Feature Overview
As a cluster-admin I want to get accurate information about the status of operators. The cluster is should not tell that portions of the cluster are Degraded or Unavailable when they're actually not. I need to see reduced false positive messaging from the status message of CVO.
Background:
This Feature is a continuation of https://issues.redhat.com/browse/OCPSTRAT-180.
Customers are asking for improvements to the upgrade experience (both over-the-air and disconnected). This is a feature tracking epics required to get that work done.
Goals
OTA-700Reduce False Positives (such as Degraded)
References
Epic Goal
- Eliminate the gap between measured availability and Available=true
Why is this important?
- Today it's not uncommon, even for CI jobs, to have multiple operators which blip through either Degraded=True or Available=False conditions
- We should assume that if our CI jobs do this then when operating in customer environments with higher levels of chaos things will be even worse
- We have had multiple customers express that they've pursued rolling back upgrades because the cluster is telling them that portions of the cluster are Degraded or Unavailable when they're actually not
- Since our product is self-hosted, we can reasonably expect that the instability that we experience on our platform workloads (kube-apiserver, console, authentication, service availability), will also impact customer workloads that run exactly the same way: we're just better at detecting it.
Scenarios
- In all of the following, assume standard 3 master 0 worker or 3 master 2+ worker topologies
- Add/update CI jobs which ensure 100% Degraded=False and Available=True for the duration of upgrade
- Add/update CI jobs which measure availability of all components which are not explicitly defined as non-HA (ex: metal's DHCP server is singleton)
- Address all identified issues
Acceptance Criteria
- openshift/enhancements CONVENTIONS outlines these requirements
- CI - Release blocking jobs include these new/updated tests
- Release Technical Enablement - N/A if we do this we should need no docs
- No outstanding identified issues
Dependencies (internal and external)
- ...
Previous Work (Optional):
- Clayton, David, and Trevor identified many issues early in 4.8 development but were unable to ensure all teams addressed them that list is in this query, teams will be asked to address everything on this list as a 4.9 blocker+ bug and we will re-evaluate status closer to 4.9 code freeze to see which may be deferred to 4.10
https://bugzilla.redhat.com/buglist.cgi?columnlist=product%2Ccomponent%2Cassigned_to%2Cbug_severity%2Ctarget_release%2Cbug_status%2Cresolution%2Cshort_desc%2Cchangeddate&f1=longdesc&f2=cf_environment&j_top=OR&list_id=12012976&o1=casesubstring&o2=casesubstring&query_based_on=ClusterOperator%20conditions&query_format=advanced&v1=should%20not%20change%20condition%2F&v2=should%20not%20change%20condition%2F
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- DEV - Tests in place
- DEV - No outstanding failing tests
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
These are alarming conditions which may frighten customers, and we don't want to see them in our own, controlled, repeatable update CI. This example job had logs like:
Feb 18 21:11:25.799 E clusteroperator/openshift-apiserver changed Degraded to True: APIServerDeployment_UnavailablePod: APIServerDeploymentDegraded: 1 of 3 requested instances are unavailable for apiserver.openshift-apiserver ()
And the job failed, but none of the failures were "something made openshift-apiserver mad enough to go Degraded".
< High-Level description of the feature ie: Executive Summary >
Goals
Cluster administrators need an in-product experience to discover and install new Red Hat offerings that can add high value to developer workflows.
Requirements
| Requirements | Notes | IS MVP |
| Discover new offerings in Home Dashboard | Y | |
| Access details outlining value of offerings | Y | |
| Access step-by-step guide to install offering | N | |
| Allow developers to easily find and use newly installed offerings | Y | |
| Support air-gapped clusters | Y |
< What are we making, for who, and why/what problem are we solving?>
Out of scope
Discovering solutions that are not available for installation on cluster
Dependencies
No known dependencies
Background, and strategic fit
Assumptions
None
Customer Considerations
Documentation Considerations
Quick Starts
What does success look like?
QE Contact
Impact
Related Architecture/Technical Documents
Done Checklist
- Acceptance criteria are met
- Non-functional properties of the Feature have been validated (such as performance, resource, UX, security or privacy aspects)
- User Journey automation is delivered
- Support and SRE teams are provided with enough skills to support the feature in production environment
Problem:
Cluster admins need to be guided to install RHDH on the cluster.
Goal:
Enable admins to discover RHDH, be guided to installing it on the cluster, and verifying its configuration.
Why is it important?
RHDH is a key multi-cluster offering for developers. This will enable customers to self-discover and install RHDH.
Acceptance criteria:
- Show RHDH card in Admin->Dashboard view
- Enable link to RHDH documentation from the card
- Quick start to install RHDH operator
- Guided flow to installation and configuration of operator from Quick Start
- RHDH UI link in top menu
- Successful log in to RHDH
Dependencies (External/Internal):
RHDH operator
Design Artifacts:
Exploration:
Note:
Description
As a cluster admin, I want to see and learn how to install Janus IDP / Red Hat Developer Hub (RHDH)
Acceptance Criteria
- Add the new Quickstart from
ODC-7418that explains how to install Janus IDP / Red Hat Developer Hub (RHDH) on the admin dashboard - Promote Pipelines and Serverless quick starts in the developer perspective (add page)
Additional Details:
Feature Overview (aka. Goal Summary)
Provide better insights into performance and frequency of OpenShift pipeline runs
Goals (aka. expected user outcomes)
Show historical and real-time pipeline run data in a unified UI panel, with drill down capabilities.
Requirements (aka. Acceptance Criteria):
Provide a visual dashboard that is competitive with leading pipeline solutions
Provide access to logs of running and historical pipeline runs
Enable in-context links to manage pipeline definitions.
Apply RBAC policies to data access.
Use Cases (Optional):
Questions to Answer (Optional):
Out of Scope
Background
Customer Considerations
Documentation Considerations
Interoperability Considerations
Outcomes:
- Dashboard is available in Admin perspective in OpenShift Console
Epic goals:
Provide a Prow dashboard similar to this: https://prow.k8s.io/
Additionally, the goal is that this work will be the beginning of the dynamic plugin for OpenShift Pipelines, which would be installed by the OpenShift Pipelines operator.
Why is it important?
- Customers want to have an admin-centric view of all PLR across namespaces.
- Customers want to see historical data on past PLR and get metrics on success/failure rate, time taken, etc.
- Currently OpenShift console as well as the Tekton dashboard does not provide them a way to correlate PR/MRs with PLR
- A single place to view the parameters for a PLR, artifacts, PLR YAML is desired.
- Customers want to achieve industry-standard DevOps metrics (DORA) from historical PLR on a repo/namespace
- Investment in Tekton Dashboard from the community will not be at par with the customer requirements coming in.
Acceptance criteria:
- Dashboard is available in Admin perspective in OpenShift Console
Dependencies (External/Internal):
Designs
Outcomes:
- Pipeline history and logs are available in dashboard for an extended time window without requiring PipelineRun CRs on the cluster
Epic goals
- Extend availability of PipelineRun history and logs beyond availability of respective custom resources on the cluster
Why is it important?
- Customers require access to pipeline history and logs for extended periods of time due to audit and troubleshooting requirements. Access to pipeline history is currently limited to the custom resources that are available on the cluster which creates an enormous burden on etcs, storage and OpenShift api server overall leading to reduced performance of the cluster.
Acceptance criteria
- Pipeline history in the dashboard displays all pipelinerun available Tekton Results data
- When user clicks on a PipelineRun, the details and logs are displayed based on the data from Tekton Results
Add a new option to the "internet proxy" to allow insecure communication that ignores CORS wit the tekton results API.
This must not be used in the final implementation! It's a workaround to start the UI developing.
Description
As a user, I want to see data from the k8s API and Tekton results API in the same list page
Acceptance Criteria
- Create ListPage component
- It should list the data from k8s API and other APIs like Tekton Results
Additional Details:
- Check with the console team if we have any plan to move ListPage component to dynamic plugin sdk.
Description
As a user, I want to see the TaskRuns from the Tekton Results data source.
Acceptance Criteria
- In the admin perspective update the TaskRuns List page to use the Tekton Results API and k8s API to get the PLRs.
- In the dev and admin perspective update the TaskRuns List in the PipelineRun details page to use Tekton Results API and k8s API to get the PLRs.
- All the features on the TaskRuns list page should work. eg: column sort, and all the options of the kebab menu
Additional Details:
Doc to install the Results on cluster https://docs.openshift-pipelines.org/operator/install-result.html
Tekton Results API swagger https://petstore.swagger.io/?url=https://raw.githubusercontent.com/avinal/tektoncd-results/openapi-fixes/docs/api/openapi.yaml
Description
As a user, I want to see the info on the details page from where PipelineRun is loaded
Acceptance Criteria
- Update the details page of the PipelineRun to use Tekton Result / k8s API from where the PipelineRun is loaded.
- Update all the tabs(logs, YAML, parameters) on the details page to use Tekton Result / k8s API from where the PipelineRun is loaded.
Additional Details:
NOTE: Events are not available in the Tekton Results API. This is only available starting with OSP 1.12+
Doc to install the Results on cluster https://docs.openshift-pipelines.org/operator/install-result.html
Tekton Results API swagger https://petstore.swagger.io/?url=https://raw.githubusercontent.com/avinal/tektoncd-results/openapi-fixes/docs/api/openapi.yaml
Description of problem:
If you delete a pipelinerun then it will be deleted in the k8s cluster but the data will be available in the tekton-results database, so the pipeline run list view will show the deleted pipelineruns
Prerequisites (if any, like setup, operators/versions):
Openshift Pipelines operator should be installed
tektonResults should be installed and working in the cluster(Follow this https://gist.github.com/vikram-raj/257d672a38eb2159b0368eaed8f8970a)
Steps to Reproduce
- Create pipeline runs
- Delete a pipeline run
Actual results:
It endlessly shows pipeline run and mentions `Resource is being deleted` in kebab menu
Expected results:
Gracefully handle it like adding a hint to the user that the Delete action will only delete it from the etcd storage and disable the delete action for results-based PLRS
Reproducibility (Always/Intermittent/Only Once):
Always
Build Details:
Workaround:
Additional info:
Slack thread: https://redhat-internal.slack.com/archives/CHG0KRB7G/p1700140684929449
Description
As a user, I want to see the info on the details page from where TaskRun is loaded
Acceptance Criteria
- Update the details page of the TaskRun to use Tekton Result / k8s API from where the TaskRun is loaded.
- Update all the tabs(logs, YAML) on the details page to use Tekton Result / k8s API from where the TaskRun is loaded.
Additional Details:
NOTE: Events are not available in the Tekton Results API. This is only available starting with OSP 1.12+
Doc to install the Results on cluster https://docs.openshift-pipelines.org/operator/install-result.html
Tekton Results API swagger https://petstore.swagger.io/?url=https://raw.githubusercontent.com/avinal/tektoncd-results/openapi-fixes/docs/api/openapi.yaml
Description
As a user, I want to see the PipelineRuns from the Tekton Results data source.
Acceptance Criteria
- In the dev and admin perspective update the PipelineRuns List page to use the Tekton Results API and k8s API to get the PLRs.
- In the dev and admin perspective update the PipelineRuns List in the Pipeline details page to use Tekton Results API and k8s API to get the PLRs.
- All the features on the list page should work. eg: column sort, and all the options of the kebab menu.
Additional Details:
Doc to install the Results on cluster https://docs.openshift-pipelines.org/operator/install-result.html
Tekton Results API swagger https://petstore.swagger.io/?url=https://raw.githubusercontent.com/avinal/tektoncd-results/openapi-fixes/docs/api/openapi.yaml
Feature Overview (aka. Goal Summary)
The MCO should properly report its state in a way that's consistent and able to be understood by customers, troubleshooters, and maintainers alike.
Some customer cases have revealed scenarios where the MCO state reporting is misleading and therefore could be unreliable to base decisions and automation on.
In addition to correcting some incorrect states, the MCO will be enhanced for a more granular view of update rollouts across machines.
The MCO should properly report its state in a way that's consistent and able to be understood by customers, troubleshooters, and maintainers alike.
For this epic, "state" means "what is the MCO doing?" – so the goal here is to try to make sure that it's always known what the MCO is doing.
This includes:
- Conditions
- Some Logging
- Possibly Some Events
While this probably crosses a little bit into the "status" portion of certain MCO objects, as some state is definitely recorded there, this probably shouldn't turn into a "better status reporting" epic. I'm interpreting "status" to mean "how is it going" so status is maybe a "detail attached to a state".
Exploration here: https://docs.google.com/document/d/1j6Qea98aVP12kzmPbR_3Y-3-meJQBf0_K6HxZOkzbNk/edit?usp=sharing
https://docs.google.com/document/d/17qYml7CETIaDmcEO-6OGQGNO0d7HtfyU7W4OMA6kTeM/edit?usp=sharing
Implementing and Merging the the new Upgrade Monitoring mechanism are to be separated. As I am working on the functionality while also wrestling with review, API migrations, and featuregate.
This card is meant to track merging the various components of the machineconfignode in the MCO.
Ensure that the pod exists but the functionality behind the pod is not exposed by default in the release version this work ships in.
This can be done by creating a new featuregate in openshift/api, vendoring that into the cluster config operator, and then checking for this featuregate in the state controller code of the MCO.
User Story:
As a user, I want to be able to:
- use external platform
- and not restrict platform name to oci only
so that I can achieve
- install OCP cluster on for external platform
Acceptance Criteria:
Description of criteria:
- No validation to restrict platform name to be oci in case of external platforms
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Feature Overview (aka. Goal Summary)
Consolidated Enhancement of HyperShift/KubeVirt Provider Post GA
This feature aims to provide a comprehensive enhancement to the HyperShift/KubeVirt provider integration post its GA release.
By consolidating CSI plugin improvements, core improvements, and networking enhancements, we aim to offer a more robust, efficient, and user-friendly experience.
Goals (aka. expected user outcomes)
- User Persona: Cluster service providers / SRE
- Functionality:
- Expanded CSI capabilities.
- Improved core functionalities of the KubeVirt Provider
- Enhanced networking capabilities.
Goal
Post GA quality of life improvements for the HyperShift/KubeVirt core
User Stories
Non-Requirements
Notes
- Any additional details or decisions made/needed
Done Checklist
| Who | What | Reference |
|---|---|---|
| DEV | Upstream roadmap issue (or individual upstream PRs) | <link to GitHub Issue> |
| DEV | Upstream documentation merged | <link to meaningful PR> |
| DEV | gap doc updated | <name sheet and cell> |
| DEV | Upgrade consideration | <link to upgrade-related test or design doc> |
| DEV | CEE/PX summary presentation | label epic with cee-training and add a <link to your support-facing preso> |
| QE | Test plans in Polarion | <link or reference to Polarion> |
| QE | Automated tests merged | <link or reference to automated tests> |
| DOC | Downstream documentation merged | <link to meaningful PR> |
In PR https://github.com/openshift/hypershift/pull/2576/ we had to disable the nodepool upgrade test. This is because there are no previous releases which have the new kubevirt rhcos variant available... so there's no release to upgrade from
We need to re-enable this test once we have a stable previously release in CI to test against (post 4.14 feature freeze and after 4.15 is branched.)
Currently there is no option to influence on the placement of the VMs of an hosted cluster with kubevirt provider. the existing NodeSelector in HostedCluster are influencing only the pods in the hosted control plane namespace.
The goal is to introduce an new field in .spec.platform.kubevirt stanza in NodePool for node selector, propagate it to the VirtualMachineSpecTemplate, and expose this in the hypershift and hcp CLIs.
kubevirt node pools currently only set requests for cpu/mem. This doesn't guarantee that the kubevirt VMs will have access to dedicated resources, which is something some customers may desire.
To resolve this, we should create a toggle on the nodepool under the kubevirt platform section to enable dedicated resources, which will give each VM guaranteed dedicated access to cpus and memory.
We need to make sure to document that multiqueue should only be used with MTU >= 9000 on the infra cluster. Smaller MTU sizes (like 1500 for example) actually displayed degraded results compared to not having multiqueue enabled at all.
CNV QE, field engineers, and developers often need to test hypershift kubevirt in a way that isn't officially supported yet, and this often involves needing to modify the kubevirt VM's spec to enable some sort of feature, add an interface/volume, or something else along those lines.
We need to design a mechanism that works as an escape hatch to allow these sorts of unsupported modifications to be experimented with easily. This mechanism should not be a part of the official Hypershift APIs, but instead something that people can influence via an annotation or similar means.
It's likely this feature will serve as a way for us to grant temporary support exceptions to customers as well.
This can be achieved using an annotation with a json patch in it. Below is an example of how such a json patch might be placed on a NodePool to influence the VMs generated by the NodePool to have a secondary interface.
apiVersion: hypershift.openshift.io/v1beta1
kind: NodePool
metadata:
annotations:
hypershift.openshift.io/kubevirt-vm-jsonpatch: |-
[
{
"op": "add",
"path": "/spec/template/spec/networks",
"value": {"name": secondary, multus: networkName: mynetwork}
},
{
"op": "add",
"path": "/spec/template/spec/domain/devices/interfaces",
"value": {"name": secondary, bridge: {}}
}
]
Goal
The goal of this epic is to provide a solution for tying HyperShift/KubeVirt vm worker nodes into networks outside of the default pod network.
An example scenario for this Epic is a user who wishes to run their KubeVirt worker node VMs on a network they have configured within their datacenter. The user already has IPAM on their network (likely through DHCP) and wishes the KubeVirt VMs for their HCP to be tied to this externally provisioned network rather than the default pod network provided by OVNKubernetes.
What is required for us in this scenario is to provide a way to configure usage of this user provided network on the NodePool, and ensuring that the capi ecosystem components (capk, cloud-provider-kubevirt) work as expected with this VM configuration
User Stories
- As a user creating and managing KubeVirt platform HCPs, I would like to control what network the KubeVirt VM worker nodes reside on.
Non-Requirements
- TODO
Notes
- Any additional details or decisions made/needed
Owners
| Role | Contact |
|---|---|
| PM | Peter Lauterbach |
| Documentation Owner | TBD |
| Delivery Owner | (See assignee) |
| Quality Engineer | (See QE Assignee) |
Done Checklist
| Who | What | Reference |
|---|---|---|
| DEV | Upstream code and tests merged | https://github.com/openshift/hypershift/pull/3066 |
| DEV | Upstream documentation merged | https://github.com/openshift/hypershift/pull/3464 |
| DEV | gap doc updated | N/A |
| DEV | Upgrade consideration | None |
| DEV | CEE/PX summary presentation | N/A |
| QE | Test plans in Polarion | N/A |
| QE | Automated tests merged | https://github.com/openshift/hypershift/pull/3449 |
| DOC | Downstream documentation merged | https://github.com/openshift/hypershift/pull/3464 |
We need the ability to configure a KubeVirt platform NodePool to use a custom network interface (not the default pod network) when creating the VMs.
Since cloud-provider-kubevirt will not be able to mirror LBs when a NodePool is not on a OVNKubernetes defined network, we'll need to make sure cloud-provider-kubevirt's LB mirroring behavior is disabled when custom networks are in use.
The scenarios that we need to cover are the ones extracted from the notes doc https://docs.google.com/document/d/1zzyHxUEPyEM4hgRh_jww4gRIKJhRTxYeKeSYhxw-pDc/edit
Scenarios
- Secondary network as single interface for VM
- Multiple Secondary Networks as multiple interfaces for VM
- Secondary network + pod network (default for kubelet) as multiple interfaces for VM
Description of problem:
hypershift kubevirt provider is missing the openshift mechanism to select what interface/ip address kubelet is going to use to register The nodeip-configuration.service should activated at MCO for kubevirt platform.
Version-Release number of selected component (if applicable):
4.15.0
How reproducible:
Always
Steps to Reproduce:
Depends on hypershift kubevirt multinet feature https://github.com/openshift/hypershift/pull/3066
1. Create an openshift libvirt/baremetal cluster with metallb, cnv, odf, local-storage and kubernetes-nmstate with a pair of extra nics at nodes
2. Populate the following network attachment definition and nncps to connect those extra nics
---
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: net1
annotations:
k8s.v1.cni.cncf.io/resourceName: bridge.network.kubevirt.io/net1
spec:
config: >
{
"cniVersion": "0.3.1",
"name": "net1",
"plugins": [{
"type": "cnv-bridge",
"bridge": "net1",
"ipam": {}
}]
}
---
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: net2
annotations:
k8s.v1.cni.cncf.io/resourceName: bridge.network.kubevirt.io/net2
spec:
config: >
{
"cniVersion": "0.3.1",
"name": "net2",
"plugins": [{
"type": "cnv-bridge",
"bridge": "net2",
"ipam": {}
}]
}
---
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: multi-net
spec:
desiredState:
interfaces:
- name: net1
type: linux-bridge
state: up
ipv4:
enabled: false
ipv6:
enabled: false
bridge:
options:
stp:
enabled: true
port:
- name: ens4
- name: net2
type: linux-bridge
state: up
ipv4:
enabled: false
ipv6:
enabled: false
bridge:
options:
stp:
enabled: true
port:
- name: ens5
3. Create a kubevirt hosted cluster using those nics with the following command --additional-network=name:default/net1 --additional-network=name:default/net2 --attach-default-network=false
Actual results:
kubelet end up expose the IP from net2 but ovn-k uses net1
Expected results:
kubelet and ovn-k should use net1
Additional info:
4.15 will only support secondary networks with the default network. The productized cli needs the `attach-default-network` cli option removed.
This cli option needs to be removed from main, 4.16, and 4.15 branches. We'll add it back once support for standalone secondary networks is supported.
Note, this is not a change to the API, only the CLI.
Goal
The goal of this epic is to introduce a validating webhook for the KubeVirt platform that executes the HostedCluster and NodePool validation at admission time.
One important note here is that the core Hypershift team has a requirement that all validation logic must be within the controller loop. This does not exclude the usage of a validation webhook, it merely means that if we introduce a validating webhook that it cannot replace the controller validation.
That means this task will involve abstracting our validation logic in a way that both the controller and our validating webhook share the same logic.
Design Document
User Stories
- As a user creating HCPs with the KubeVirt platform, i want to discover validation errors at creation time rather than through a condition on the HostedCluster and NodePool objects after creation.
Non-Requirements
Notes
- Any additional details or decisions made/needed
Done Checklist
| Who | What | Reference |
|---|---|---|
| DEV | Upstream roadmap issue (or individual upstream PRs) | <link to GitHub Issue> |
| DEV | Upstream documentation merged | <link to meaningful PR> |
| DEV | gap doc updated | <name sheet and cell> |
| DEV | Upgrade consideration | <link to upgrade-related test or design doc> |
| DEV | CEE/PX summary presentation | label epic with cee-training and add a <link to your support-facing preso> |
| QE | Test plans in Polarion | <link or reference to Polarion> |
| QE | Automated tests merged | <link or reference to automated tests> |
| DOC | Downstream documentation merged | <link to meaningful PR> |
The underlying infa cluster hosting HCP KubeVirt worker VMs must meet some versioning requirements (cnv >= 4.14, ocp >= 4.14). There is a validation check that enforces this on the backend today. WE'd like to move this validation to a webhook so users get early feedback if the validation will fail during Creation.
The hypershift operator only supports specific versions of release payloads. We'd like to give users early feedback by validating that the release payload they have picked falls within the backend operator' supported window.
The backend controller loop performs this check here. We'd like the same check to be introduced into an optional validating webhook.
Goal
Currently, the Hypershift's HostedCluster and NodePool APIs are difficult to use directly. The "hcp" cli alleviates this complexity to some degree, but comes at the cost of requiring usage of a cli tool rather than creating the resources directly.
The Goal of this epic is to reduce the complexity of the HostedCluster and NodePool APIs to the point that users only need to specify a small set of values in these apis initially at create time, then during admission have a mutating webhook fill in the remaining details using the defaults that the "hcp" cli currently uses.
Essentialy, the goal here is to move the "magic" defaulting that is so convenient to users out of the "hcp" tool and to the hypershift operator backend using a mutation webhook.
User Stories
- As a user creating self-managed HCP clusters, I would like to create an HCP using only HostedCluster and NodePool resources and have the backend controllers generate the etcd and ssh key secrets on my behalf
- As a user creating self-managed HCP clusters, I’d like to provide a minimal HostedCluster and NodePool spec and have the backend perform all the platform specific defaulting at creation time.
Non-Requirements
Notes
- WIP design document https://docs.google.com/document/d/1lFknxPASyGGGyurjLmGvXV5JJKJ-WnOSncMm7ej-gI4/edit
Done Checklist
| Who | What | Reference |
|---|---|---|
| DEV | Upstream roadmap issue (or individual upstream PRs) | <link to GitHub Issue> |
| DEV | Upstream documentation merged | <link to meaningful PR> |
| DEV | gap doc updated | <name sheet and cell> |
| DEV | Upgrade consideration | <link to upgrade-related test or design doc> |
| DEV | CEE/PX summary presentation | label epic with cee-training and add a <link to your support-facing preso> |
| QE | Test plans in Polarion | <link or reference to Polarion> |
| QE | Automated tests merged | <link or reference to automated tests> |
| DOC | Downstream documentation merged | <link to meaningful PR> |
All HC and NP API defaulting within the hcp cli that impacts the KubeVirt platform should be moved to CRD defaulting and mutating webhooks
Today the hcp cli tool is rendering an etcd encryption secret for each cluster that is created. We'd like for the backend to perform this logic so users can more easily use the HostedCluster API directly without needing the cli tool.
Feature Overview (aka. Goal Summary)
In a multi-tenant, both ICSP and IDMS objects should be functional in the cluster at the same time.
Goals (aka. expected user outcomes)
Enable both ICSP and IDMS objects to exist on the cluster at the same time and roll out both configurations.
Requirements (aka. Acceptance Criteria):
ICSP and IDMS objects should be functional
Provide the ICSP to IDMS migration path without node reboot which can lead to disruption.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- As an ICSP user on an ongoing cluster, I want to migrate to IDMS without breaking current workloads or removing ICSP/creating IDMS objects manually.
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Do not error out if both ICSP IDMS resources exist.
MCO waches both ICSP, IDMS objects. As an openshift developer, I want it to process content from both kind CRD to underlying configuration.
Feature Overview
- Customers want to create and manage OpenShift clusters using managed identities for Azure resources for authentication.
- In Phase 2, we want to iterate on the CAPI-related items for ARO/Azure managed identity work, e.g. to update cluster-api-provider-azure to consume Azure workload identity tokens, Update ARO Credentials Request manifest of the Cluster CAPI Operator to use new API field for requesting permissions .
User Goals
- A customer using ARO wants to spin up an OpenShift cluster with "az aro create" without needing additional input, i.e. without the need for an AD account or service principal credentials, and the identity used is never visible to the customer and cannot appear in the cluster.
- As an administrator, I want to deploy OpenShift 4 and run Operators on Azure using access controls (IAM roles) with temporary, limited privilege credentials.
Requirements
- Azure managed identities must work for installation with all install methods including IPI and UPI, work with upgrades, and day-to-day cluster lifecycle operations.
- Support HyperShift and non-HyperShift clusters.
- Support use of Operators with Azure managed identities.
- Support in all Azure regions where Azure managed identity is available. Note: Federated credentials is associated with Azure Managed Identity, and federated credentials is not available in all Azure regions.
More details at ARO managed identity scope and impact.
This Section: A list of specific needs or objectives that a Feature must deliver to satisfy the Feature.. Some requirements will be flagged as MVP. If an MVP gets shifted, the feature shifts. If a non MVP requirement slips, it does not shift the feature.
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
(Optional) Use Cases
This Section:
- Main success scenarios - high-level user stories
- Alternate flow/scenarios - high-level user stories
- ...
Questions to answer…
- ...
Out of Scope
- …
Background, and strategic fit
This Section: What does the person writing code, testing, documenting need to know? What context can be provided to frame this feature.
Assumptions
- ...
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
References
- https://learn.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview
- https://docs.microsoft.com/en-us/azure/active-directory/develop/workload-identity-federation
- https://docs.microsoft.com/en-us/azure/active-directory/develop/workload-identities-overview
- https://learn.microsoft.com/en-us/azure/aks/workload-identity-overview
Epic to capture the items not blocking for OCPSTRAT-506 (OCPBU-8)
Evaluate if any of the ARO predefined roles in the credentials request manifests of OpenShift cluster operators give elevated permissions. Remove any such predefined role from spec.predefinedRoles field and replace it with required permissions in the new spec.permissions field.
Feature Overview (aka. Goal Summary)
As a result of Hashicorp's license change to BSL, Red Hat OpenShift needs to remove the use of Hashicorp's Terraform from the installer – specifically for IPI deployments which currently use Terraform for setting up the infrastructure.
Goals (aka. expected user outcomes)
Remove use of Terraform in the IPI Installer from the top providers: AWS, vSphere, Metal, and Azure.
Requirements (aka. Acceptance Criteria):
The IPI Installer no longer contains or uses Terraform.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal
- Enact a strategy to comply with license changes around Terraform and handle any CVEs that may arise (within Terraform) during the process of replacing Terraform.
Two major parts:
- Get AWS off Terraform (for ROSA)
- Strategy for all other platforms that stay on terraform
Why is this important?
- Hashicorp will continue to backport CVE fixes to MPL versions of Terraform through the end of 2023. After that period, we will not be able to address any CVEs within Terraform through upgrades. This epic provides a strategy to use until we can remove Terraform entirely from the product.
Scenarios
- AWS: due to FedRamp compliance within ROSA, will need to fix any medium CVE–exploitable or not.
- Backporting (see open questions)
Acceptance Criteria
- AWS platform must be able to fix all medium CVEs, regardless of whether they are exploitable
- All other platforms must be able to handle CVEs based on our normal practices
- ...
Dependencies (internal and external)
- If we decide to produce a ROSA-specific build (as expected), ROSA and Hive will need to be able to consume a separate installer binary.
Previous Work (Optional):
Open questions::
- Priority of backporting CVE fixes
- Can we get more concrete about standards for fixing CVEs
- What would managing our own Terraform fork entail
- Can we remove the alibaba provider? This would be helpful to decrease vulnerabilities.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
The installer should support feature gate validation so that new providers can be enabled via featuregates.
Create an installer image to be promoted to the release payload that contains the openshift altinfra binary (produced with build tags).
User Story:
I want to be able to produce an openshift-install binary for installing AWS (other platforms will not be supported) which is free of Terraform.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
Encapsulate Terraform to its own package (removing dependencies from pkg/asset and cmd) so that Terraform can be included or removed based on build tags.
Interface provides a way of substituting other infrastructure providers.
Acceptance Criteria:
Description of criteria:
- Investigate the difficulties associated with backporting
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Epic Goal
- Provision AWS infrastructure without the use of Terraform
Why is this important?
- This is a key piece in producing a terraform-free binary for ROSA. See parent epic for more details.
Scenarios
- The new provider should aim to provide the same results as the existing AWS terraform provider.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- Switch all AWS installations to use SDK implementation rather than Terraform
Why is this important?
- Currently, AWS SDK installations are only available by using the separate `installer-altinfra` image. This change would switch all users to use the SDK installation method.
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Epic Goal
- Add an API extension for North-South IPsec.
- close gaps from
SDN-3604- mainly around upgrade - add telemetry
Why is this important?
- without API, customers are forced to use MCO. this brings with it a set of limitations (mainly reboot per change and the fact that config is shared among each pool, can't do per node configuration)
- better upgrade solution will give us the ability to support a single host based implementation
- telemetry will give us more info on how widely is ipsec used.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- Must allow for the possibility of offloading the IPsec encryption to a SmartNIC.
- nmstate
- k8s-nmstate
- easier mechanism for cert injection (??)
- telemetry
Dependencies (internal and external)
Related:
- ITUP-44 - OpenShift support for North-South OVN IPSec
- HATSTRAT-33 - Encrypt All Traffic to/from Cluster (aka IPSec as a Service)
Previous Work (Optional):
SDN-717- Support IPSEC on ovn-kubernetesSDN-3604- Fully supported non-GA N-S IPSec implementation using machine config.
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Feature Overview (aka. Goal Summary)
oc, the openshift CLI, needs as close to feature parity as we can get without the built-in oauth server and its associated user and group management. This will enable scripts, documentation, blog posts, and knowledge base articles to function across all form factors and the same form factor with different configurations.
Goals (aka. expected user outcomes)
CLI users and scripts should be usable in a consistent way regardless of the token issuer configuration.
Requirements (aka. Acceptance Criteria):
A list of specific needs or objectives that a feature must deliver in order to be considered complete. Be sure to include nonfunctional requirements such as security, reliability, performance, maintainability, scalability, usability, etc. Initial completion during Refinement status.
Use Cases (Optional):
Include use case diagrams, main success scenarios, alternative flow scenarios. Initial completion during Refinement status.
Questions to Answer (Optional):
Include a list of refinement / architectural questions that may need to be answered before coding can begin. Initial completion during Refinement status.
Out of Scope
High-level list of items that are out of scope. Initial completion during Refinement status.
Background
Provide any additional context is needed to frame the feature. Initial completion during Refinement status.
Customer Considerations
Provide any additional customer-specific considerations that must be made when designing and delivering the Feature. Initial completion during Refinement status.
Documentation Considerations
Provide information that needs to be considered and planned so that documentation will meet customer needs. If the feature extends existing functionality, provide a link to its current documentation. Initial completion during Refinement status.
Interoperability Considerations
Which other projects, including ROSA/OSD/ARO, and versions in our portfolio does this feature impact? What interoperability test scenarios should be factored by the layered products? Initial completion during Refinement status.
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
oc login needs to work without the embedded oauth server
Why is this important? (mandatory)
We are removing the embedded oauth-server and we utilize a special oauthclient in order to make our login flows functional
This allows documentation, scripts, etc to be functional and consistent with the last 10 years of our product.
This may require vendoring entire CLI plugins. It may require new kubeconfig shapes.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be “Release Pending”
Manual cherry-pick work to backport the changes merged in 4.16
Epic Goal*
What is our purpose in implementing this? What new capability will be available to customers?
`oc whoami` must work without the oauth-apiserver. There is an endpoint recently added to kube that allows congruent functionality.
Why is this important? (mandatory)
The oauth-apiserver does not control IdP information when external OIDC is used. this means the oauth-apiserver is no longer deployed. This causes `oc whoami` to fail.
Scenarios (mandatory)
Provide details for user scenarios including actions to be performed, platform specifications, and user personas.
Dependencies (internal and external) (mandatory)
What items must be delivered by other teams/groups to enable delivery of this epic.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be "Release Pending"
Feature Overview (aka. Goal Summary)
As part of the deprecation progression of the openshift-sdn CNI plug-in, remove it as an install-time option for new 4.15+ release clusters.
Goals (aka. expected user outcomes)
The openshift-sdn CNI plug-in is sunsetting according to the following progression:
- deprecation notice delivered at 4.14 (Release Notes, What's Next presentation)
- removal as an install-time option at 4.15+
- removal as an option and EOL support at 4.17 GA
Requirements (aka. Acceptance Criteria):
- The openshift-sdn CNI plug-in will no longer be an install-time option for newly installed 4.15+ clusters across installation options.
- Customer clusters currently using openshift-sdn that upgrade to 4.15 or 4.16 with openshift-sdn will remain fully supported.
- EUS customers using openshift-sdn on an earlier release (e.g. 4.12 or 4.14) will still be able to upgrade to 4.16 and receive full support of the openshift-sdn plug-in.
Questions to Answer (Optional):
- Will clusters using openshift-sdn and upgrading from earlier versions to 4.15 and 4.16 still be supported?
- YES
- My customer has a hard requirement for the ability to install openshift-sdn 4.15 clusters. Is there any exceptions to support that?
- Customers can file a Support Exception for consideration, and the reason for the requirement (expectation: rare) must be clarified.
Out of Scope
Background
All development effort is directed to the default primary CNI plug-in, ovn-kubernetes, which has feature parity with the older openshift-sdn CNI plug-in that has been feature frozen for the entire 4.x timeframe. In order to best serve our customers now and in the future, we are reducing our support footprint to the dominant plug-in, only.
Documentation Considerations
- Product Documentation updates to reflect the install-time option change.
Epic Goal
The openshift-sdn CNI plug-in is sunsetting according to the following progression:
- deprecation notice delivered at 4.14 (Release Notes, What's Next presentation)
- removal as an install-time option at 4.15+
- removal as an option and EOL support at 4.17 GA
Why is this important?
All development effort is directed to the default primary CNI plug-in, ovn-kubernetes, which has feature parity with the older openshift-sdn CNI plug-in that has been feature frozen for the entire 4.x timeframe. In order to best serve our customers now and in the future, we are reducing our support footprint to the dominant plug-in, only.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- The openshift-sdn CNI plug-in will no longer be an install-time option for newly installed 4.15+ clusters across installation options.
- Customer clusters currently using openshift-sdn that upgrade to 4.15 or 4.16 with openshift-sdn will remain fully supported.
- EUS customers using openshift-sdn on an earlier release (e.g. 4.12 or 4.14) will still be able to upgrade to 4.16 and receive full support of the openshift-sdn plug-in.
Open questions::
- Will clusters using openshift-sdn and upgrading from earlier versions to 4.15 and 4.16 still be supported?
- YES
- My customer has a hard requirement for the ability to install openshift-sdn 4.15 clusters. Is there any exceptions to support that?
- Customers can file a Support Exception for consideration, and the reason for the requirement (expectation: rare) must be clarified.
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Have OpenShiftSDN (openshift-sdn CNI plug-in) no longer be an option for networkType, making the only supported value for the network OVNKubernetes
so that I can achieve
- The removal of the openshift-sdn CNI plug-in at install-time for 4.15+
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional)[ https://github.com/openshift/enhancements/blob/master/enhancements/network/sdn-live-migration.md#rollback|https://github.com/openshift/enhancements/blob/master/enhancements/network/sdn-live-migration.md#rollback]
- https://github.com/openshift/installer/blob/f60ebb065b4242586f7afacc5f2be8afddbdfbde/pkg/types/validation/installconfig.go#L333C1-L333C85
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Outcome/Feature Overview (aka. Goal Summary)
Enrich the OpenShift Pipelines experience for DevSecOps and Software Supply Chain Security use cases such as CVEs, SBOMs and signatures.
Goals (aka. expected user outcomes)
Improving application developer experience when using OpenShift Pipelines by increasing awareness of important SSCS elements. An OpenShift Pipelines PipelineRun's Task can emit CVEs, SBOMs, policy reporting as well as identify signing status.
Requirements (aka. Acceptance Criteria):
- CVE Summary as a column in PipelineRun list view
- Link to SBOM for PipelineRuns
- Add a badge/icon for chains.tekton.dev/signed=true for PipelineRuns
Problem:
Enrich the OpenShift Pipelines experience for DevSecOps and Software Supply Chain Security use cases such as CVEs, SBOMs and signatures.
Goal:
Improving application developer experience when using OpenShift Pipelines by increasing awareness of important SSCS elements. An OpenShift Pipelines PipelineRun's Task can emit CVEs, SBOMs, policy reporting as well as identify signing status.
Acceptance criteria:
- CVE Summary as a column in PipelineRun list view
- Link to SBOM for PipelineRuns
- Add a badge/icon for chains.tekton.dev/signed=true for PipelineRuns
- Move pipelinerun results section to output tab using static tab extension point.
Dependencies (External/Internal):
Design Artifacts:
Miro link - here
Exploration:
Project GUI enhancements doc
Description
As a user, I want to see the SBOM link in the pipelinerun details page and if the pipelinerun is signed by chains then a signed badge should appear next to the pipelinerun name.
Acceptance Criteria
- If a pipelinerun has produced an SBOM, then show the SBOM section in the pipelinerun details page.
- Pipelineruns that are signed by chains should be indicated by a signed badge.
Additional Details:
Tekton results annotation to be used - https://docs.google.com/document/d/1_1YXFx0ymzjl4b9M_LDjmmGrEYey5mDrfTdNn_56hpM/edit#heading=h.u0j4yw1zdczm
Description
As a user, I want to see the vulnerabilities in the OCP console, so that I can identify and fix the issue as early as possible.
Acceptance Criteria
- Show the Vulnerabilities column in the pipelinerun list page.
- UI should use the new tekton results naming conventions (find the link below).
- UI needs to aggregate all the results that contain the string SCAN_OUTPUT. eg: ROXCTL_SCAN_OUTPUT, ACS_SCAN_OUTPUT.
- Show signed badge next to the pipelinerun name if it is signed by chains.
- Show View SBOM link in the kebab menu, if the pipeline run has SBOM attached to it.
Additional Details:
Tekton results naming conventions - doc
Batch the tekton results API request to avoid performance issues and use pagination to fetch the vulnerabilities when a user scrolls down in the list page.
Note: A pipelinerun can have multiple results SCAN_OUTPUT results.
Description
As a user, I would like to see all the pipelinerun results in a new Output tab.
Acceptance Criteria
- Move the Pipelinerun results section to the. new Output tab.
- Use extension point to add the output tab, so that it can be overwritten later via dynamic plugin.
Additional Details:
Slack thread - https://redhat-internal.slack.com/archives/C060FCC5KU1/p1699442229040389?thread_ts=1699441759.578729&cid=C060FCC5KU1
Address technical debt around self-managed HCP deployments, including but not limited to
- CA ConfigMaps into the trusted bundle for both the CPO and Ignition Server, improving trust and security.
- Create dual stack clusters through CLI with or without default values, ensuring flexibility and user preference in network management.
- Utilize CLI commands to disable default sources, enhancing customizability.
- Benefit from less intrusive remote write failure modes,.
- ...
The CLI cannot create dual stack clusters with the default values. We need to create the proper flags to enable the HostedCluster to be a dual stack one using the default values
This can be based on the exising CAPI agent provider workflow which already has an env var flag for disconnected
User Story:
As a (user persona), I want to be able to:
- HCP CLI can create dual stack cluster with CIDRs
so that I can achieve
- We can directly use HCP CLI to create dual stack cluster.
Acceptance Criteria:
Description of criteria:
- Can directly use HCP CLI to create dual stack cluster.
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
By default Agent provider is creating clusters delegating on the CLI, this is not bad, but if you don't define the UpgradeType as a CLI argument it will default to Replace which is basically the focus for cloud providers. We need to default the UpgradeType for Agent provider to InPlace but also respect the option set from the CLI. We also need to check with Kubevirt team what is the desired default.
Customer has escalated the following issues where ports don't have TLS support. This Feature request lists all the components port raised by the customer.
Details here https://docs.google.com/document/d/1zB9vUGB83xlQnoM-ToLUEBtEGszQrC7u-hmhCnrhuXM/edit
Currently, we are serving the metrics as http on 9258 we need to upgrade to use TLS
To solve this, use Kube RBAC proxy as a side container to proxy the metrics and provide an authentication/authorization layer for the metrics
Related to https://issues.redhat.com/browse/RFE-4665
Background
CCMO metrics are currently exposed on a non-TLS server.
We should only expose the metrics via a TLS server.
Use Kube RBAC Proxy (as inspired by other components, eg MAO) to expose metrics via TLS, keeping non-TLS connections only on the localhost.
Steps
- Add a kube-rbac-proxy container to the CCMO
- Ensure the non-TLS port is moved down by 1
- Ensure the host port registry accounts for the non TLS port
Stakeholders
- Cluster Infra
- Subin M
Definition of Done
- CCMO runs kube-rbac-proxy alongside its current containers and only exposes metrics via the TLS port
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Currently, we are serving the metrics as http on 9191, and via TLS on 9192.
We need to make sure the metrics are only available on 9192 via TLS.
Related to https://issues.redhat.com/browse/RFE-4665
Background
CMA currently exposes metrics on two ports via the 0.0.0.0 all hosts binding. We need to make sure that only the TLS port is accessible from outside localhost.
Steps
- Move the binding for the local metrics server to localhost only
- Ensure kube-rbac-proxy is still proxying the requests over TLS
Stakeholders
- Cluster Infra
- Subin M
Definition of Done
- Metrics from CMA are only exposed over TLS
- Docs
- <Add docs requirements for this card>
- Testing
- <Explain testing that will be added>
Epic Goal*
There was an epic / enhancement to create a cluster-wide TLS config that applies to all OpenShift components:
https://issues.redhat.com/browse/OCPPLAN-4379
https://github.com/openshift/enhancements/blob/master/enhancements/kube-apiserver/tls-config.md
For example, this is how KCM sets --tls-cipher-suites and --tls-min-version based on the observed config:
https://issues.redhat.com/browse/WRKLDS-252
https://github.com/openshift/cluster-kube-controller-manager-operator/pull/506/files
The cluster admin can change the config based on their risk profile, but if they don't change anything, there is a reasonable default.
We should update all CSI driver operators to use this config. Right now we have a hard-coded cipher list in library-go. See OCPBUGS-2083 and OCPBUGS-4347 for background context.
Why is this important? (mandatory)
This will keep the cipher list consistent across many OpenShift components. If the default list is changed, we get that change "for free".
It will reduce support calls from customers and backport requests when the recommended defaults change.
It will provide flexibility to the customer, since they can set their own TLS profile settings without requiring code change for each component.
Scenarios (mandatory)
As a cluster admin, I want to use TLSSecurityProfile to control the cipher list and minimum TLS version for all CSI driver operator sidecars, so that I can adjust the settings based on my own risk assessment.
Dependencies (internal and external) (mandatory)
None, the changes we depend on were already implemented.
Contributing Teams(and contacts) (mandatory)
Our expectation is that teams would modify the list below to fit the epic. Some epics may not need all the default groups but what is included here should accurately reflect who will be involved in delivering the epic.
- Development -
- Documentation -
- QE -
- PX -
- Others -
Acceptance Criteria (optional)
Provide some (testable) examples of how we will know if we have achieved the epic goal.
Drawbacks or Risk (optional)
Reasons we should consider NOT doing this such as: limited audience for the feature, feature will be superseded by other work that is planned, resulting feature will introduce substantial administrative complexity or user confusion, etc.
Done - Checklist (mandatory)
The following points apply to all epics and are what the OpenShift team believes are the minimum set of criteria that epics should meet for us to consider them potentially shippable. We request that epic owners modify this list to reflect the work to be completed in order to produce something that is potentially shippable.
- CI Testing - Basic e2e automationTests are merged and completing successfully
- Documentation - Content development is complete.
- QE - Test scenarios are written and executed successfully.
- Technical Enablement - Slides are complete (if requested by PLM)
- Engineering Stories Merged
- All associated work items with the Epic are closed
- Epic status should be "Release Pending"
- https://github.com/openshift/alibaba-disk-csi-driver-operator/pull/72
- https://github.com/openshift/csi-operator/pull/71
- https://github.com/openshift/azure-disk-csi-driver-operator/pull/110
- https://github.com/openshift/azure-file-csi-driver-operator/pull/84
- https://github.com/openshift/cluster-storage-operator/pull/415
- https://github.com/openshift/csi-driver-manila-operator/pull/212
- https://github.com/openshift/gcp-pd-csi-driver-operator/pull/97
- https://github.com/openshift/openstack-cinder-csi-driver-operator/pull/143
- https://github.com/openshift/vmware-vsphere-csi-driver-operator/pull/190
Goal:
As an administrator, I would like to use my own managed DNS solution instead of only specific openshift-install supported DNS services (such as AWS Route53, Google Cloud DNS, etc...) for my OpenShift deployment.
Problem:
While cloud-based DNS services provide convenient hostname management, there's a number of regulatory (ITAR) and operational constraints customers face prohibiting the use of those DNS hosting services on public cloud providers.
Why is this important:
- Provides customers with the flexibility to leverage their own custom managed ingress DNS solutions already in use within their organizations.
- Required for regions like AWS GovCloud in which many customers may not be able to use the Route53 service (only for commercial customers) for both internal or ingress DNS.
- OpenShift managed internal DNS solution ensures cluster operation and nothing breaks during updates.
Dependencies (internal and external):
- DNS work for KNI
- https://docs.google.com/document/d/1VsukDGafynKJoQV8Au-dvtmCfTjPd3X9Dn7zltPs8Cc/edit
- This is a prerequisite for the internal clusters epic: https://docs.google.com/document/d/1gxtIW6OlasVQtQLTyOl6f9H9CMuxiDNM5hQFNd3xubE/edit#
Prioritized epics + deliverables (in scope / not in scope):
- Ability to bootstrap cluster without an OpenShift managed internal DNS service running yet
- Scalable, cluster (internal) DNS solution that's not dependent on the operation of the control plane (in case it goes down)
- Ability to automatically propagate DNS record updates to all nodes running the DNS service within the cluster
- Option for connecting cluster to customers ingress DNS solution already in place within their organization
Estimate (XS, S, M, L, XL, XXL):
Previous Work:
Open questions:
Link to Epic: https://docs.google.com/document/d/1OBrfC4x81PHhpPrC5SEjixzg4eBnnxCZDr-5h3yF2QI/edit?usp=sharing
User Story:
As a (user persona), I want to be able to:
- depend on OpenShift to self-host its DNS for api, api-int and ingress during the bootstrap process
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github.com/openshift/enhancements/pull/1468
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github/com/link.to.enhancement/
- (optional) https://issues.redhat.com/link.to.spike
- Engineering detail 1
- Engineering detail 2
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Append Infra CR with only the GCP PlatformStatus field (without any other fields esp the Spec) set with the LB IPs at the end of the bootstrap ignition. The theory is that when Infra CR is applied from the bootstrap ignition, first the infra manifest is applied. As we progress through all the other assets in the ignition files, Infra CR appears again but with only the LB IPs set. That way it will update the existing Infra CR already applied to the cluster.
User Story:
As a (user persona), I want to be able to:
- Capability 1
- Capability 2
- Capability 3
so that I can achieve
- Outcome 1
- Outcome 2
- Outcome 3
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
Detail about what is specifically not being delivered in the story
Engineering Details:
- (optional) https://github.com/openshift/enhancements/pull/1468
- (optional) https://issues.redhat.com/link.to.spike
- https://github.com/openshift/baremetal-runtimecfg is responsible for generating the Corefile for CoreDNS. Supply the API and API-Int LB IP addresses to baremetal-runtimecfg using new optional flags: "cloud-ext-lb-ips" and "cloud-int-lb-ips".
- When these input parameters are present, generate the CoreDNS Corefile with entries for api and api-int urls using these LB IP addresses.
![]() This requires/does not require a design proposal.
This requires/does not require a design proposal.
![]() This requires/does not require a feature gate.
This requires/does not require a feature gate.
Use the API, API-Int and Ingress LB IPs within GCPPlatformStatus instead of the `lb-config` ConfigMap to generate the in cluster CoreDNS pods.
OCP/Telco Definition of Done
Epic Template descriptions and documentation.
<--- Cut-n-Paste the entire contents of this description into your new Epic --->
Epic Goal
- At this point in the feature, we would have a working in-cluster CoreDNS pod capable of resolving API and API-Int URLs.
This Epic details that work required to augment this CoreDNS pod to also resolve the *.apps URL. In addition, it will include changes to prevent Ingress Operator from configuring the cloud DNS after the ingress LBs have been created.
Why is this important?
- …
Scenarios
- ...
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- ...
Dependencies (internal and external)
- ...
Previous Work (Optional):
- …
Open questions::
- …
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
User Story:
As a (user persona), I want to be able to:
- Create a Writeable asset or Asset to represent the config map for load balancer information
- No current asset dependencies
- Create a function `CreateLBConfigMap` that accepts the name, internal lb data, public lb data, and platform name. The function will return the string representation of the config map
so that I can achieve
- A Config Map that will be loaded onto cluster nodes during installation for custom dns solutions.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
If a zone has not been granted permission to be shared across projects (if in different projects), then the install will fail.
User Story:
As a (user persona), I want to be able to:
- Create a Writeable asset or Asset to represent the config map for load balancer information
- No current asset dependencies
- Create a function `CreateLBConfigMap` that accepts the name, internal lb data, public lb data, and platform name. The function will return the string representation of the config map
so that I can achieve
- A Config Map that will be loaded onto cluster nodes during installation for custom dns solutions.
Acceptance Criteria:
Description of criteria:
- Upstream documentation
- Point 1
- Point 2
- Point 3
(optional) Out of Scope:
If a zone has not been granted permission to be shared across projects (if in different projects), then the install will fail.
Feature Overview (aka. Goal Summary)
Support ARO and customers aspiring to follow Microsoft Azure security recommendations by allowing the Azure storage account hosting the object storage bucket for the integrated registry to be configured as "private" vs. the default public.
Goals (aka. expected user outcomes)
OpenShift installations on Azure can be configured so that they don't trigger the Azure's Security Advisor anymore with regard to the use of a public endpoint for the Azure storage account created by the integrated registry operator.
Requirements (aka. Acceptance Criteria):
- Manual private storage account configuration via the Integrated Registry operator's CR
- Automatic discovery of vnet and subnet resources requiring the end user to only set a single flag of the Integrated Registry operator CR to "internal"
Background
Several users noticed warnings in Azure Security advisor reporting the potentially dangerous exposure of the storage endpoint used by the integrated registry configured by its operator. There is no real security threat here because despite the endpoint being public, access to it is strictly locked down to a single set of credentials used by the internal registry only.
Still customers need to be able to deploy cluster that out of the box do not violate Microsoft security recommendations.
This feature sets the foundation for OCPSTRAT-997 to be delivered.
Customer Considerations
Customers updating to the version of OpenShift that delivers this feature shall not have their integrated registry configuration updated automatically.
Documentation Considerations
We require documentation in the section for the integrated registry operator that describes how to manually configure the vnet and subnet that shall be used for the private storage endpoint in case the customer wants to leverage an network resource group account different from the cluster.
We also require documentation that describes the single tunable for the integrated registry operator that is required to be set to "internal" to automate the detection of existing vnet and subnets in the network resource group of the cluster as opposed to manual specification of a user-defined vnet/subnet pair.
Epic Goal
- Enable customers to create an OpenShift IPI deployment on Azure that does not violate Microsoft Azure Security recommendations
Why is this important?
- In the current implementation the OpenShift internal registry operator creates a storage account for the backing image blob store of the registry that has a public endpoint
- the public endpoint is considered insecure by Azure's Security advisor and prevents customers from completing security-relevant certifications
- while manual remediation is possible it is not acceptable for customers who want to leverage OpenShift IPI capabilities to deploy many clusters as automated and with as little post-install infrastructure customisation as possible
Scenarios
- The openshift-installer allows the user to specify VNet and Subnet names to be used for a private endpoint of the storage account, this setting requires the user to specify that they want to create private storage account instead of a public one
- If the user configured to creation of a private storage account, the integrated registry operators uses the user-specified VNet and Subnet names as input and creates a private storage account in Azure using a private endpoint with the supplied VNet and Subnet
- The current implementation of creating a storage account with a public endpoint remains the default if nothing else is configured
Acceptance Criteria
- A user can enable the creation of a private storage account in Azure for the internal registry via the openshift installer
- A user must supply a VNet and Subnet name if they opted into private storage accounts
- The internal registry creates an Azure storage account with a private endpoint if the user opted into private storage accounts using the supplied VNet and Subnet names
- Private storage accounts are not the default
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
- Installer allows to specify VNet and Subnet names for a private storage account on Azure
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
Story: As an image registry developer, I want to be able to programmatically create a private endpoint in Azure without having to worry about explicitly creating the supporting objects, so that I can easily enable support for private storage accounts in Azure.
ACCEPTANCE CRITERIA
When the registry is in private mode:
- Private endpoint is created in Azure
- Private DNS zone is created in Azure
- Record Set (type A) is created in Azure
- Private DNS Zone Group is created in Azure
- Virtual Network Link is created between Private Endpoint and VNet
- Configuring the registry to use a private endpoint, then setting it to "Removed" should delete the private endpoint from Azure.
DOCUMENTATION
- No documentation is needed at this point
The installer currently does not tag subnets and vnet pre-created by users (and by itself?) on Azure.
Background
When "Publish: Internal", the image registry operator needs to discover subnets and vnet the cluster was provisioned with, so that it can provision a private storage account for the registry to use.
Story: As a user, I want to be able to configure the registry operator to use Azure Private Endpoints so that I can deploy the registry on Azure without a public facing endpoint.
ACCEPTANCE CRITERIA
- There is an option to configure the registry operator to deploy the registry privately on Azure (this should not be available to other cloud providers)
- When configuring the operator to deploy the registry privately, the user is also required to provide names for the cluster's VNet and Subnet for the operator to configure the private endpoint in
- Configuring the operator to make the registry private also disables public access network in the storage account
Setting the registry back to public deletes the private endpoint and enables public access again- The operand's conditions reflects any errors that might happen during this procedure
- When the registry is configured with private endpoints, pulling images from the registry outside of OCP will only work by first setting "disableRedirect: true" (assuming a route is configured)
DOCUMENTATION
- Update post-installation docs for private clusters on Azure
- Placement of this docs needs further investigation, as the post-install for private clusters does not seem cloud provider specific and we need this one to be just for Azure.
- Installer documentation for private clusters on Azure should not be updated (there is no supported way to enable this feature through installer-config at this point)
- The procedure to configure the registry to private should also mention that pulling images from the registry using the default route (provided by setting `defaultRoute: true`) will no longer work UNLESS customers set `disableRedirect: true` in the operator configuration.
Feature Overview
Reduce the OpenShift platform and associated RH provided components to a single physical core on Intel Sapphire Rapids platform for vDU deployments on SingleNode OpenShift.
Goals
- Reduce CaaS platform compute needs so that it can fit within a single physical core with Hyperthreading enabled. (i.e. 2 CPUs)
- Ensure existing DU Profile components fit within reduced compute budget.
- Ensure existing ZTP, TALM, Observability and ACM functionality is not affected.
- Ensure largest partner vDU can run on Single Core OCP.
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
| Release Technical Enablement | Provide necessary release enablement details and documents. | YES |
| Provide a mechanism to tune the platform to use only one physical core. |
Users need to be able to tune different platforms. | YES |
| Allow for full zero touch provisioning of a node with the minimal core budget configuration. | Node provisioned with SNO Far Edge provisioning method - i.e. ZTP via RHACM, using DU Profile. | YES |
| Platform meets all MVP KPIs | YES |
(Optional) Use Cases
- Main success scenario: A telecommunications provider uses ZTP to provision a vDU workload on Single Node OpenShift instance running on an Intel Sapphire Rapids platform. The SNO is managed by an ACM instance and it's lifecycle is managed by TALM.
Questions to answer...
- N/A
Out of Scope
- Core budget reduction on the Remote Worker Node deployment model.
Background, and strategic fit
Assumptions
- The more compute power available for RAN workloads directly translates to the volume of cell coverage that a Far Edge node can support.
- Telecommunications providers want to maximize the cell coverage on Far Edge nodes.
- To provide as much compute power as possible the OpenShift platform must use as little compute power as possible.
- As newer generations of servers are deployed at the Far Edge and the core count increases, no additional cores will be given to the platform for basic operation, all resources will be given to the workloads.
Customer Considerations
- ...
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Administrators must know how to tune their Far Edge nodes to make them as computationally efficient as possible.
- Does this feature have doc impact?
- Possibly, there should be documentation describing how to tune the Far Edge node such that the platform uses as little compute power as possible.
- New Content, Updates to existing content, Release Note, or No Doc Impact
- Probably updates to existing content
- If unsure and no Technical Writer is available, please contact Content Strategy. What concepts do customers need to understand to be successful in [action]?
- Performance Addon Operator, tuned, MCO, Performance Profile Creator
- How do we expect customers will use the feature? For what purpose(s)?
- Customers will use the Performance Profile Creator to tune their Far Edge nodes. They will use RHACM (ZTP) to provision a Far Edge Single-Node OpenShift deployment with the appropriate Performance Profile.
- What reference material might a customer want/need to complete [action]?
- Performance Addon Operator, Performance Profile Creator
- Is there source material that can be used as reference for the Technical Writer in writing the content? If yes, please link if available.
- N/A
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
- Likely updates to existing content / unsure